Oracle’s Big Data Platform goes Cloud, Becomes Elastic and Suddenly Looks Very Interesting.
Oracle held their annual Openworld customer event last week in San Francisco, and amongst all the other cloud services, infrastructure and other new products Oracle announced over the various keynotes, for me the most interesting thing was the Thomas Kurian cloud innovation keynote on Tuesday where Jeff Pollock came on to demonstrate Oracle’s new Elastic Big Data & Streaming platform, around 30 mins into the video below:
https://players.brightcove.net/1460825906/VkKNQZg6x_default/index.html?videoId=5133872292001
Those of you who follow what cloud platform vendors such as Microsoft and Amazon are doing to provide Hadoop and analytics services (HD Insight for Microsoft Azure, Elastic MapReduce for Amazon AWS) will recognise the similar approach Oracle are taking to the base Infrastructure-as-a-Service layer; as Thomas Kurian shows below before Jeff comes on, familiar Hadoop components (Spark, Hive, ML, Spark SQL) run through YARN and store data in an object store (think S3) running in an elastic cloud environment. What’s new for Oracle customers is consuming Hadoop and data lake functionality as services managed and exposed through APIs, a more abstracted approach that makes it possible to elastically scale the service up-and-down and offer lower initial price-points to startups and kick-the-tires customers creating data lakes in the cloud without any formal IT approval.

Note also Hortonworks in the diagram rather than Cloudera, Oracle’s Hadoop platform partner up until now. This could be because Hortonworks’ HDP platform suits being turned into services better than Cloudera’s, or they offered a better deal for what I’d imagine is mostly open-source products with Hortonworks committers and associated support — or more probably because Cloudera are moving increasingly into cloud services themselves, and seem to be aligning with Amazon and Microsoft’s cloud platforms rather than Oracle’s, as I noted in a tweet earlier today:
[embed]https://twitter.com/markrittman/status/781147091921952768[/embed]
As I said, offering Hadoop as services on an elastic cloud platform is nothing new, just tables stakes if Oracle wants to be in this game (and they do). Where things then got interesting is when the demo and the tooling came out. First off was a packaged industry IoT application using predictive analytics to tell the customer which device or sensor is likely to fail before it actually does, giving them the chance to repair or replace the component before there’s a service outage. So far, standard stuff though the execution and UX looked slick, something Oracle are increasingly good at if what you last saw was Oracle Forms and Java applets in the browser.
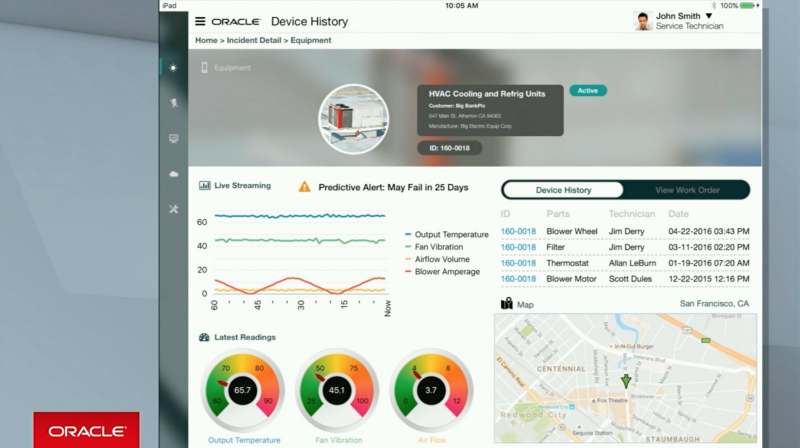
Then we got on to the underlying services that provide data and insights for the IoT packaged app. You’ve probably seen articles and blogs I’ve written on Oracle’s Big Data Preparation Cloud Service tool, but Data Flow Machine Learning is Oracle’s long-anticipated cloud data integration service that uses dataflow-style mappings, Spark as the execution engine and machine-learning smarts and semantic discovery to automate as much of the development process as possible — this paper back from Spark Summit 2015 explains some of the supervised and semi-supervised machine learning algorithms that Oracle (via their Silver Creek Systems acquisition) used when creating their cloud data prep service.

Then the demo moved on to setting up data ingestion services using Kafka and Spark services running real-time and streaming, and then showed target schemas being defined and created automatically for the user.

And then it got on to Data Flow Machine Learning…
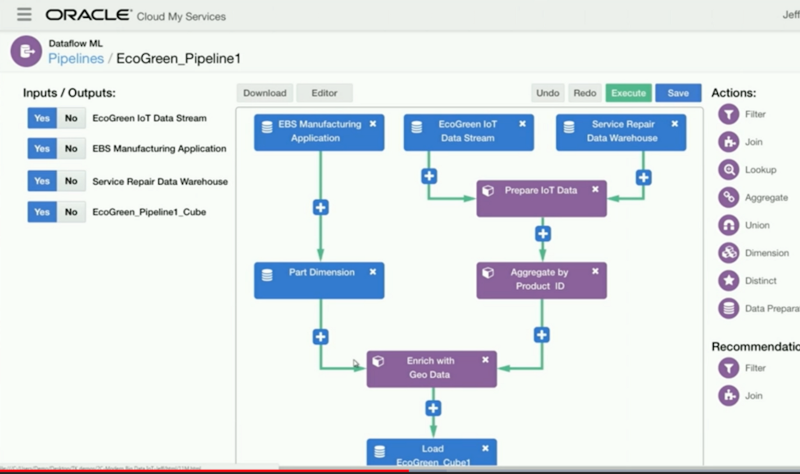
… and that’s worthy of a blog post all of it’s own given how significant it’s going to be going forward, and I’ll post that in a day or so’s time.