Oracle Big Data Cloud, Event Hub and Analytics Cloud Data Lake Edition pt.1
Some time ago I posted a blog on what analytics and big data development looked like on Google Cloud Platform using Google BigQuery as my data store and Looker as the BI tool, with data sourced from social media, wearable and IoT data sources routed through a Fluentd server running on Google Compute Engine. Overall, the project architecture looked like the diagram below…
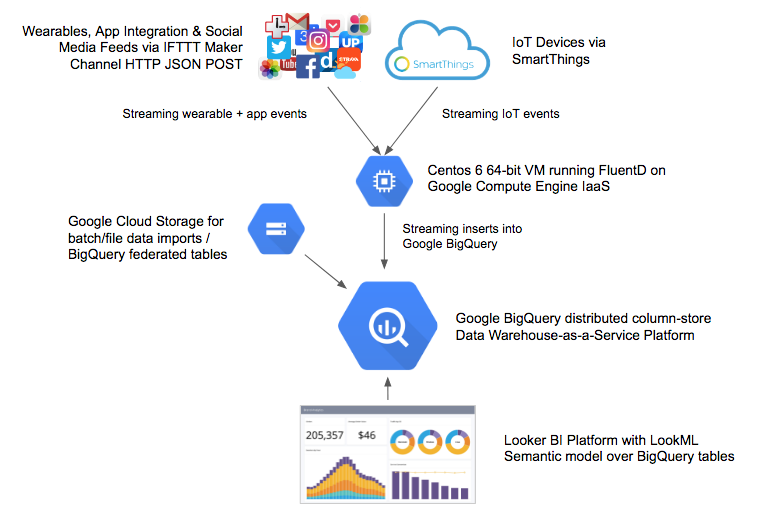
… and I’ve got more-or-less the same setup running right now, with an additional GCE VM running Confluent Open Source to feed a subset of the event streams into a Druid cluster that I’m using to test out Looker, Superset and Imply for sub-second ad-hoc query analysis use-cases. More on that soon.
If you’re a regular reader of this blog you might recall a week or so ago I posted a blog on the new releases of Oracle Business Intelligence Enterprise Edition (OBIEE), Oracle Analytics Cloud (OAC) and Oracle Data Visualization Desktop (DVD) and mentioned a new packaging option for their cloud analytics product, Oracle Analytics Cloud Data Lake Edition. I’ve got a particular interest in what this product might be as I used to use the product it replaces, Oracle Big Data Discovery (BDD), fairly extensively in Oracle big data analytics and data lake projects a few years ago.
And Oracle Big Data Discovery was — technically at least — a great product. It combined the search and analytics features of Endeca Information Discovery with the scale and data transformation abilities enabled by Apache Spark and Hadoop, but suffered perhaps by being a bit ahead of the market and by not having any obvious integration with the rest of Oracle’s analytics and data management tools. By contrast Oracle Analytics Cloud Data Lake Edition is one of three packaging options for Oracle Analytics Cloud and includes all of the functionality of OAC Standard Edition (Oracle Data Visualization together with basic data preparation tools) as well as itself being a subset of the wider set of analysis, dashboarding and enterprise data modeling features in OAC Enterprise Edition.
An equivalent product architecture for ingesting, transforming and analyzing my IoT, wearables and social media data in Oracle Cloud would look something like the diagram below, with the following Oracle Cloud Platform-as-a-Service (PaaS) products used for ingest, storage and analysis:
- Oracle Event Hub Cloud Service: Apache Kafka running either customer or Oracle-managed with full access to Kafka’s REST Proxy and Kafka Connect
- Oracle Big Data Cloud: Oracle’s new elastically-scalable Hadoop platform running Apache Spark, Ambari and other Hortonworks Data Platform components
- Oracle Analytics Cloud Data Lake Edition: Oracle Data Visualization combined with more extensive lightweight ETL (“data flow”) components, text analytics and machine learning model training and build capabilities

In this example I’m using Apache Hive and Parquet storage as my column-orientated data platform but of course I’ve now also got Oracle Autonomous Data Warehouse Cloud as an option; I’ll stick with Hive on Oracle Big Data Cloud for now though as this gives me the option to use Apache Spark to transform and wrangle my data and for building machine learning models using SparkML and, via pySpark, Python Pandas. In what’s the first of two posts in this short series I’ll be looking at how the data pipeline is set up, and then in the second post I’ll look at Oracle Analytics Cloud Data Lake Edition in detail focusing on the data transformation, data engineering and data science features it adds beyond OAC Standard Edition.
The development environment I put together for this scenario used the following Oracle Infrastructure-as-a-Service (IaaS) and Platform-as-a-Service (PaaS) components:
- Oracle Compute Classic and Storage Classic Services
- Oracle Database Cloud Service, with the 11g database option
- Oracle Event Hub Cloud Service Dedicated, with Kafka Connect and REST Proxy nodes
- Oracle Big Data Cloud, single node with Hive, Spark 2.1, Tez, HDFS, Zookeeper, Zeppelin, Pig and Ambari
- Oracle Analytics Cloud Data Lake Edition with Self Service Data Preparation, Visualisation and Smart Discovery (aka Oracle DV)
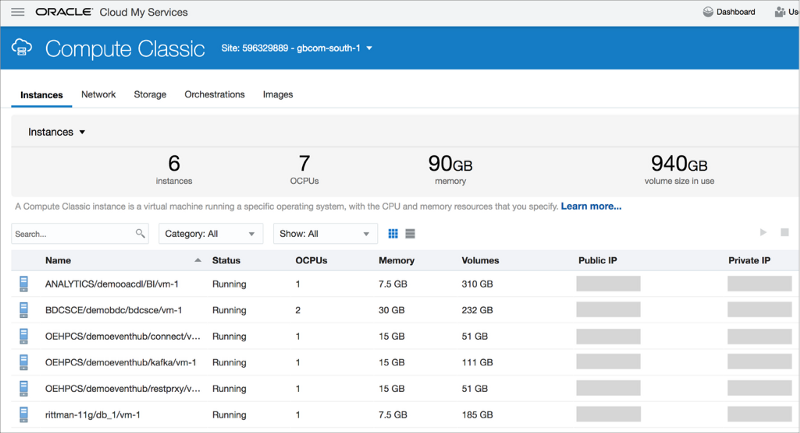
The screenshot below from the Compute Classic Service Console shows the various PaaS VMs running on the compute IaaS layer, with other tabs in this console showing network, storage and other infrastructure service usage.
The order in which you install the services is important if you want to associate the various products together correctly, and if like me you’re using a trial account you’ll need to plan carefully to ensure you keep with the various quota limits that Oracle Cloud imposes on trial identity domains that stopped me, for example, allocating the usual two OCPUs to the main Oracle Event Hub Kafka server if I wanted to run the rest of the stack at the same time.
Associating two services together, for example Oracle Event Hub and Oracle Big Data Cloud, connects the two services together automatically in the identity domain network and makes using them together much simpler but unless Event Hub Cloud is provisioned and available when you come to install Big Data Cloud you can’t go back and associate them afterwards, but more annoyingly if you decide you want to use Event Hub Cloud and associate it with Big Data Cloud but since then you’ve provisioned Oracle Analytics Cloud Data Lake Edition and associated Big Data Cloud with that you have to unwind the whole provisioning process and start again with Event Hub Cloud if you want to connect them all together properly. And forget deleting that Database Cloud Service you associated with Oracle Big Data Cloud and then forgot about as you can’t delete services that other services are associated with.
Provisioning each of the services involves giving the service instance a name, assigning storage buckets and OCPU counts to the various cluster nodes you request, and at key points selecting previously provisioned and now running services for association with the one you’re now provisioning. The screenshots below show the three-stage provisioning service for Event Hub Cloud Service — Dedicated:

and the order in which I provisioned my data lake services, and the important options I chose to make it all work together and within quota, were as follows:
- First ensure you have access to Oracle Cloud, and then the various IaaS services: Oracle Cloud Infrastructure Compute Classic, Oracle Cloud Infrastructure Object Storage Classic and Oracle Identity Cloud Service
- Provision Oracle Database Cloud Service to store the various Fusion Middleware RCU schemas; in my case I chose Oracle Database 11gR2 as the database type as it avoids the complexity around CDBs and PDBs you get with the 12c database release
- Then provision Oracle Event Hub Cloud — Dedicated with one OCPU for the main Kafka VM, one for the REST Proxy VM and another one OCPU for the Kafka Connect VM. For a real deployment you’d want at least two OCPUs for the Kafka service VM but using just the one kept me within my overall OCPU quota limit when installing the rest of the stack
- Next step is to provision Big Data Cloud with a single node with the minimum 2 OCPUs, the Full deployment profile and version 2.1 of Apache Spark as that’s the version OAC Data Lake Edition insist on in the next step. When prompted, choose the option to associate Event Hub Cloud and Database Cloud with Big Data Cloud as you won’t get the option to do this again after the initial service provision; once provisioned, open-up the TCP port for Ambari (8080) to the public internet so that OAC in the next step can associate with it — provisioning for OAC failed for me every time until I looked through the provisioning logs and spotted this as the issue
- Finally, provision Oracle Analytics Cloud and choose Data Lake Edition as the package option, again in my case assigning a single OCPU and selecting Data Lake Edition as the software version
At that point if you then bring up the Cloud Services dashboard and review the services together for the first time, it’ll look something like this:

Now it’s time to ingest some data and land it into Oracle Big Data Cloud.
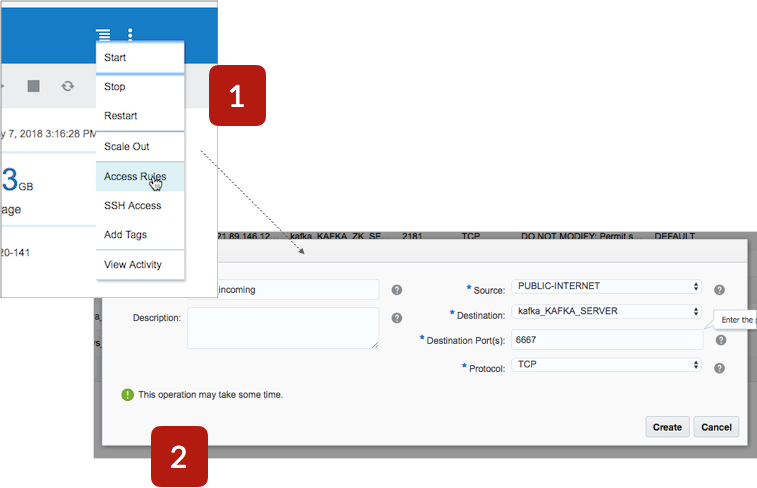
The streaming IoT, wearables and social media comms data that I’ll be ingesting into Big Data Cloud will be coming in from the public internet over TCP, and I’ll also want to connect to Event Hub Cloud from my desktop using tools such as Kafka Tool so an addition configuration step I’ll do before setting up anything else is to open-up Event Hub Cloud’s Kafka broker endpoint to the public internet using the Access Rules menu item in the Event Hub Cloud console.
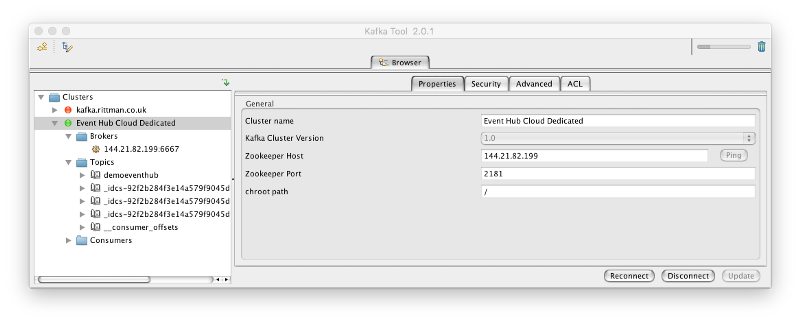
Now I can see the Kafka service and the default topics that Event Hub Service created for me in Kafka tool.
I can either then use Kafka tool to create a new topic to start receiving the first of my data streams, the IoT device event data coming out of Samsung SmartThings, or create the topic as by defining a new Event Hub Cloud service from within the Event Hub Cloud Service — Dedicated console (confusing, but that’s how Kafka topics are named within Event Hub Cloud)

Then it’s just a case of directing the stream of IoT event data to the public Kafka broker endpoint exposed by Event Hub Cloud Service — Dedicated and then, after a short while, checking the metrics for the new Kafka topic that I setup to receive this incoming streaming data.

Getting the data off the Kafka topic and into a Hive table on the Big Data Cloud instance involved the following steps, using Oracle Cloud Infrastructure Object Storage Classic as the intermediate staging layer together with Event Hub Kafka Connect’s OCS Sink Connector:
- Configure Event Hub Kafka Connect OCS Sink Connector to push topic events to Oracle Cloud Infrastructure Object Storage Classic (OCS)
- Using Zeppelin notebook provided by Big Data Cloud Console, create a CRON job that copies those events across to HDFS storage
- Create Hive external tables with location clauses that point to the directories I’ve copied the event files into from OCS
Then, when I go and log into OAC Data Lake Edition and connect to the Hive Thrift Server on the Big Data Cloud instance I can see the Hive tables I’ve just created, and the data that’s now streaming through from my two initial sources via the Kafka service and Kafka Connect running on Event Hub Cloud Service — Dedicated.
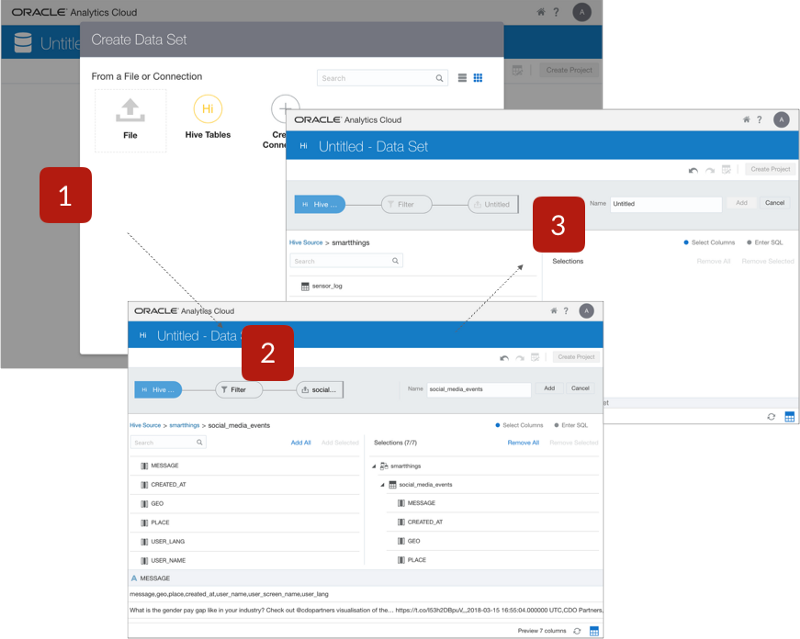
In the second half of this two-post series I’ll go deeper into OAC Data Lake Edition and see how its additional transformation and analysis capabilities stack-up against OAC Standard Edition, and also see how it compares to the Oracle Big Data Discovery tool its looking to eventually replace.