Coalesce 2023 and the new dbt Cloud CLI
Coalesce 2023 happened a couple of weeks ago in San Diego, London and Sydney and the Rittman Analytics team travelled over to the San Diego event as our annual offsite get-together.
Last year’s Coalesce was all about the Semantic Layer, and whilst dbt Labs came back to the topic with the v2, relaunched version of their semantic layer incorporating MetricFlow technology courtesy of the Transform acquisition earlier in the year, the feature that I'm the most excited to try out is the new dbt cloud cli.
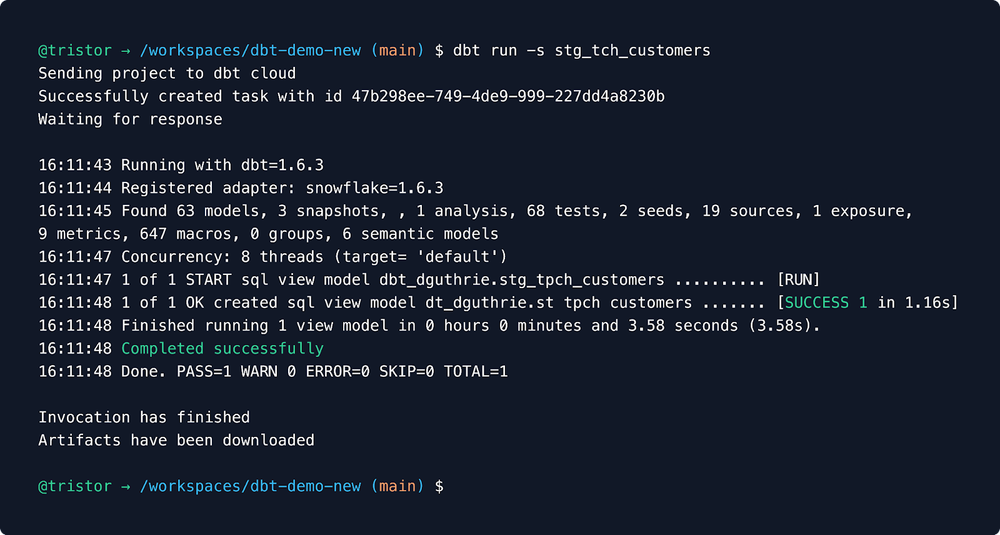
You can now leverage dbt cloud functionality for a more streamlined development workflow without stripping power users of the ergonomics that come with using their IDE of choice (mine: vscode).
The dbt cloud cli is a separate Python package which overwrites dbt-core. They cannot coexist in an environment because they share the dbt namespace when it comes to commands such as dbt run or dbt test.
After installing the package and connecting to your environments in dbt cloud, cli commands will be sent to those cloud instances rather than processing on your computer. Even if the changes to your code are only saved locally and not yet pushed to origin with git, dbt cloud will still process them. That should make it easy to forget that you're not using dbt-core, because your workflow can be exactly the same.
Or, it would be, if it weren't for the fact that dbt cloud processing enables more streamlined access to advanced features. There's some good stuff around not having to tinker with warehouse connection details in your profiles.yml and the new cross-project ref. However I am most excited for the prospect of automatic deferral. From dbt’s docs:
“Defer is a powerful feature that allows developers to only build and run and test models they've edited without having to first run and build all the models that come before them (upstream parents). This is powered by using a production manifest for comparison, and dbt will resolve the {{ ref() }} function with upstream production artifacts.”
This can save you warehouse spend and time by automatically only running your changed models and reading from production tables / views where possible.
The problem with doing it in dbt-core is that you need access to the production manifest. Making sure that the representative manifest file you have locally is up-to-date with the production one requires consideration and development setup. However, if your queries are being executed in dbt cloud then it handles that process for you. Thus, now you can have easy access to defer without sacrificing your power user ergonomics.
The python package is installed with e.g. pip3 install dbt and its installation name here is interesting. The fact that it aligns more closely with the product's brand name (simply, "dbt") implies to me that there might be a deliberate positioning of this package by dbt Labs as the default way people will interface with their dbt projects going forward. "I'm not sure what core refers to but I'm supposed to be installing dbt, so I guess this is the right one". New users stumbling upon the tool might increasingly only ever know dbt’s cloud offering as this workflow matures and docs get rewritten with cloud-focused recommended steps.
Finally, I do also want to highlight the excellent talk by Niall Woodward and lan Whitestone from SELECT.dev that’s available now to view on their website. It is apparent that they have a deep knowledge of query optimisation and investigation, especially on Snowflake. Their presentation struck a great balance between technical specifics and understandability. The recording of it is definitely a resource I'll refer to a lot.
Recommended Posts
An Homage to Oracle Warehouse Builder, 25 Years Ahead of Its Time
Why We’ve Tried to Replace Data Analytics Developers Every Decade Since 1974
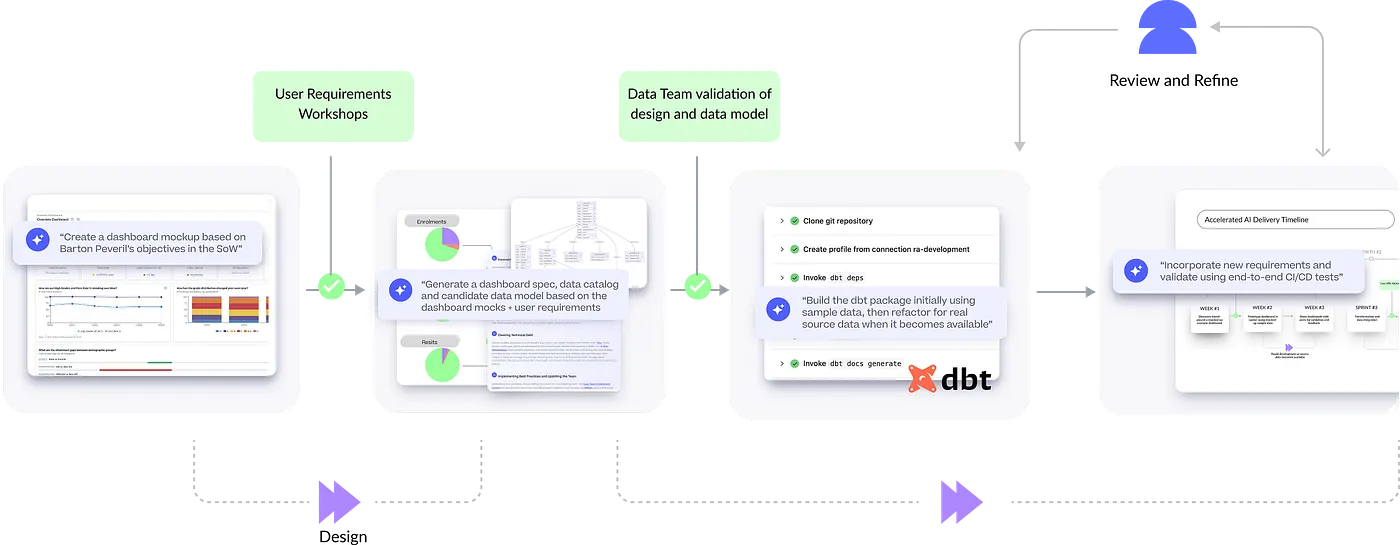
How Rittman Analytics uses AI-Augmented Project Delivery to Provide Value to Users, Faster
