-
Not FoundBlog post not found
 Rittman Analytics Blog
Rittman Analytics Blog
Latest thoughts on data analytics, customer insights, and industry trends
Data Platform Implementation
Data Strategy Framework
Data Team Modernisation
Embedded Analytics
Expert Services
Generative AI Solutions
From the Archives

Hell Freezes-Over as Oracle Exadata, Autonomous Database (and OCI) become Available on Google Cloud Platform
Jun 25, 2024
Is Your Business Ready and Enabled For Generative AI?
Sep 2, 2024

Roll with It with Cube, Embeddable and Rittman Analytics on Monday, 16th September 2024 : London RSA House, Durham Street Auditorium
Sep 5, 2024
Group by:
Sort by:
Latest Posts
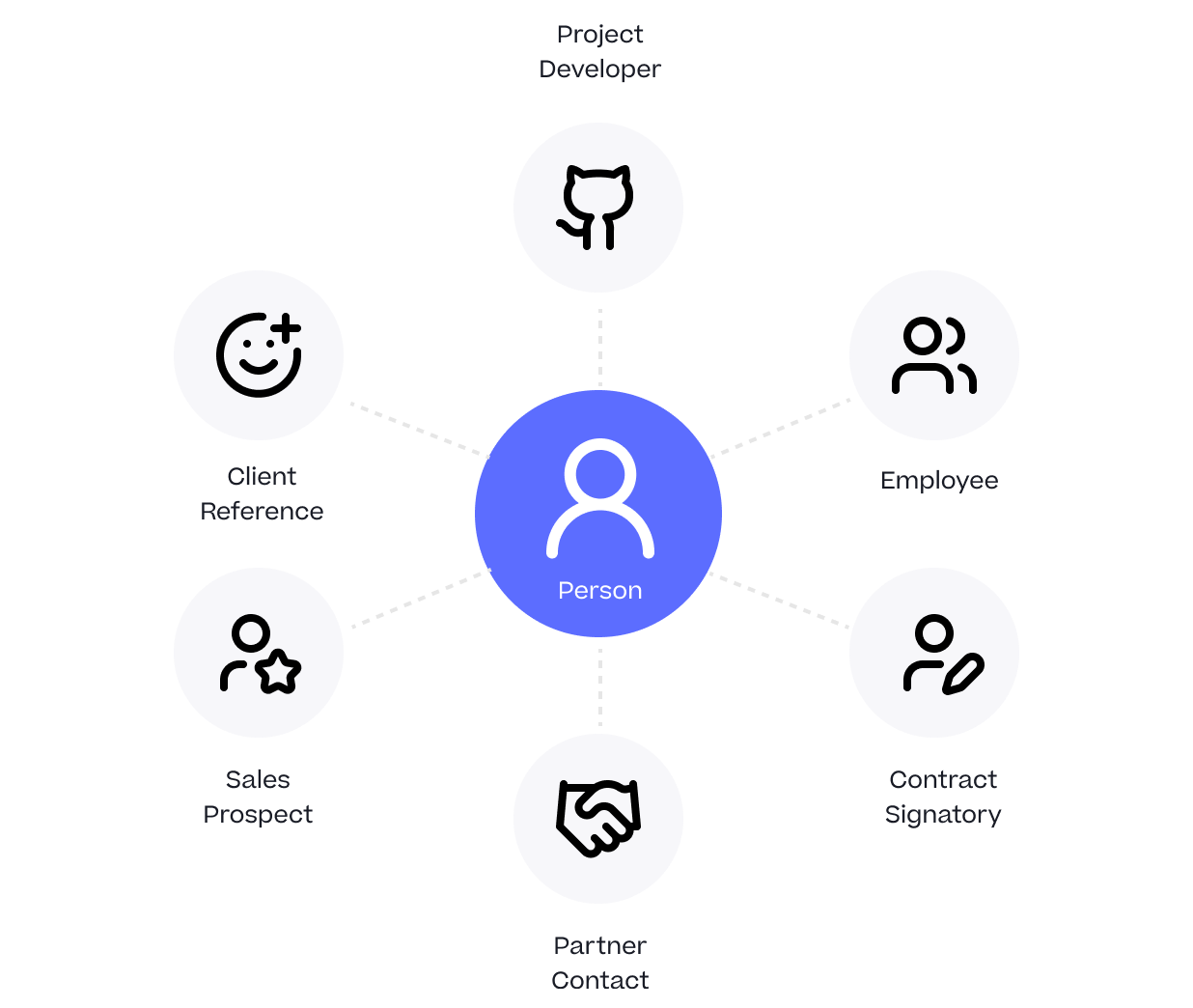
One Person Many Roles: Designing a Unified Person Dimension in Google BigQuery
Jan 26, 2026
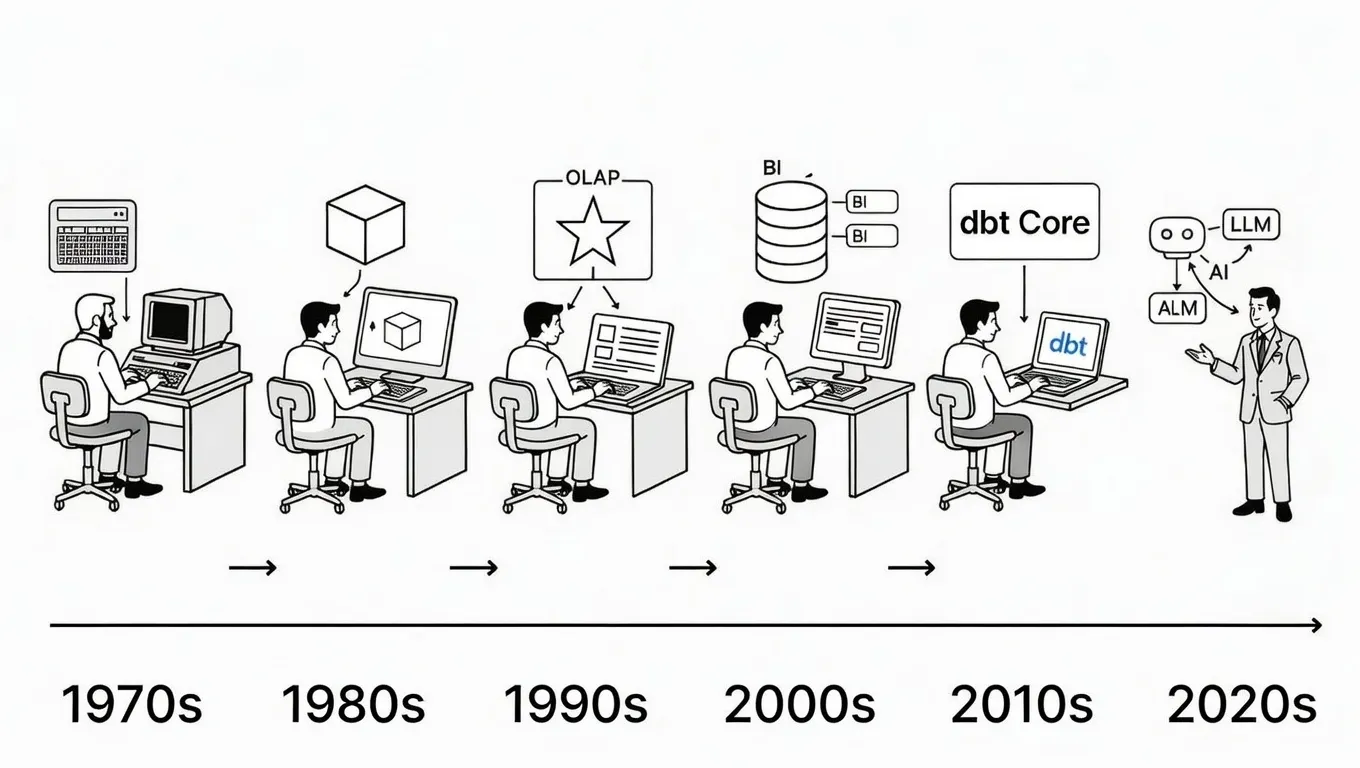
Why We’ve Tried to Replace Data Analytics Developers Every Decade Since 1974
Jan 19, 2026
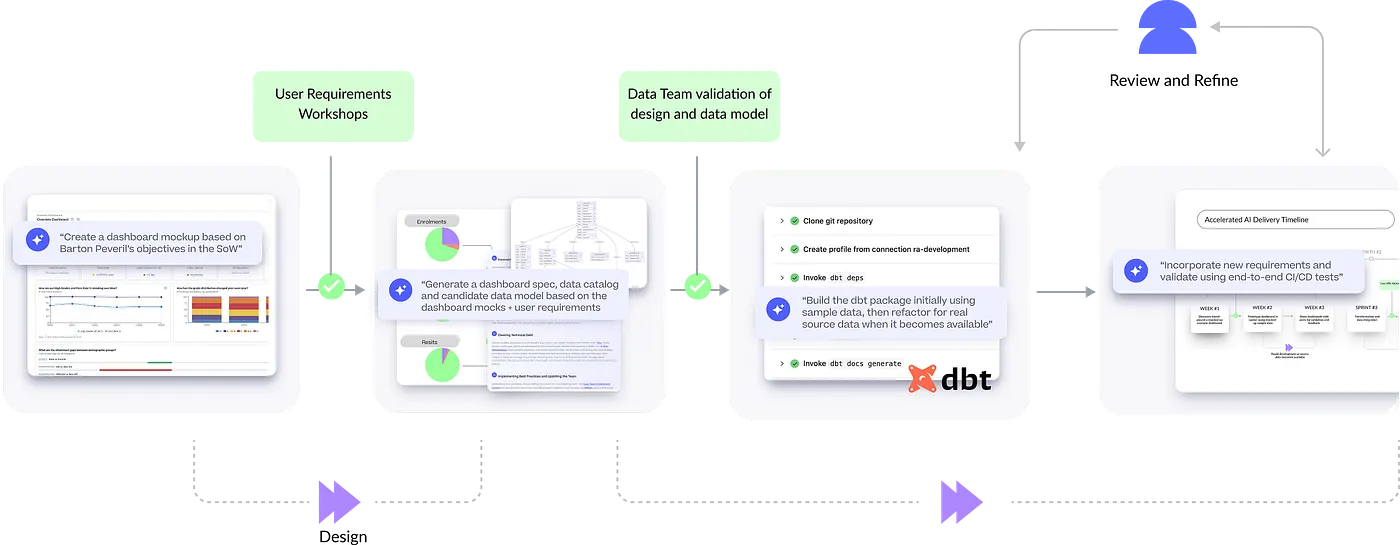
How Rittman Analytics uses AI-Augmented Project Delivery to Provide Value to Users, Faster
Jan 19, 2026

Rittman Analytics 2025 Wrapped : A Year of Platforms, People and High-Performing Data Teams
Jan 19, 2026

You Probably Don’t Need an RFP
Jan 19, 2026
Claude Meets Looker: Building Smarter, Connected Analytics with Google’s MCP Toolbox
Dec 8, 2025
From Prompts to Skills: Automating Financial and KPI Analysis in Looker with Claude Skills and MCP Toolbox
Dec 8, 2025
An Homage to Oracle Warehouse Builder, 25 Years Ahead of Its Time
Dec 8, 2025
Google Integrates Spectacles into Looker for Continuous Integration & Regression Testing
Sep 8, 2025
How Rittman Analytics Does Financial Analytics using Looker, Fivetran and Google BigQuery
Sep 7, 2025

Rittman Analytics is Riding from London to Brighton, 14th September 2025 for the British Heart Foundation
Sep 2, 2025
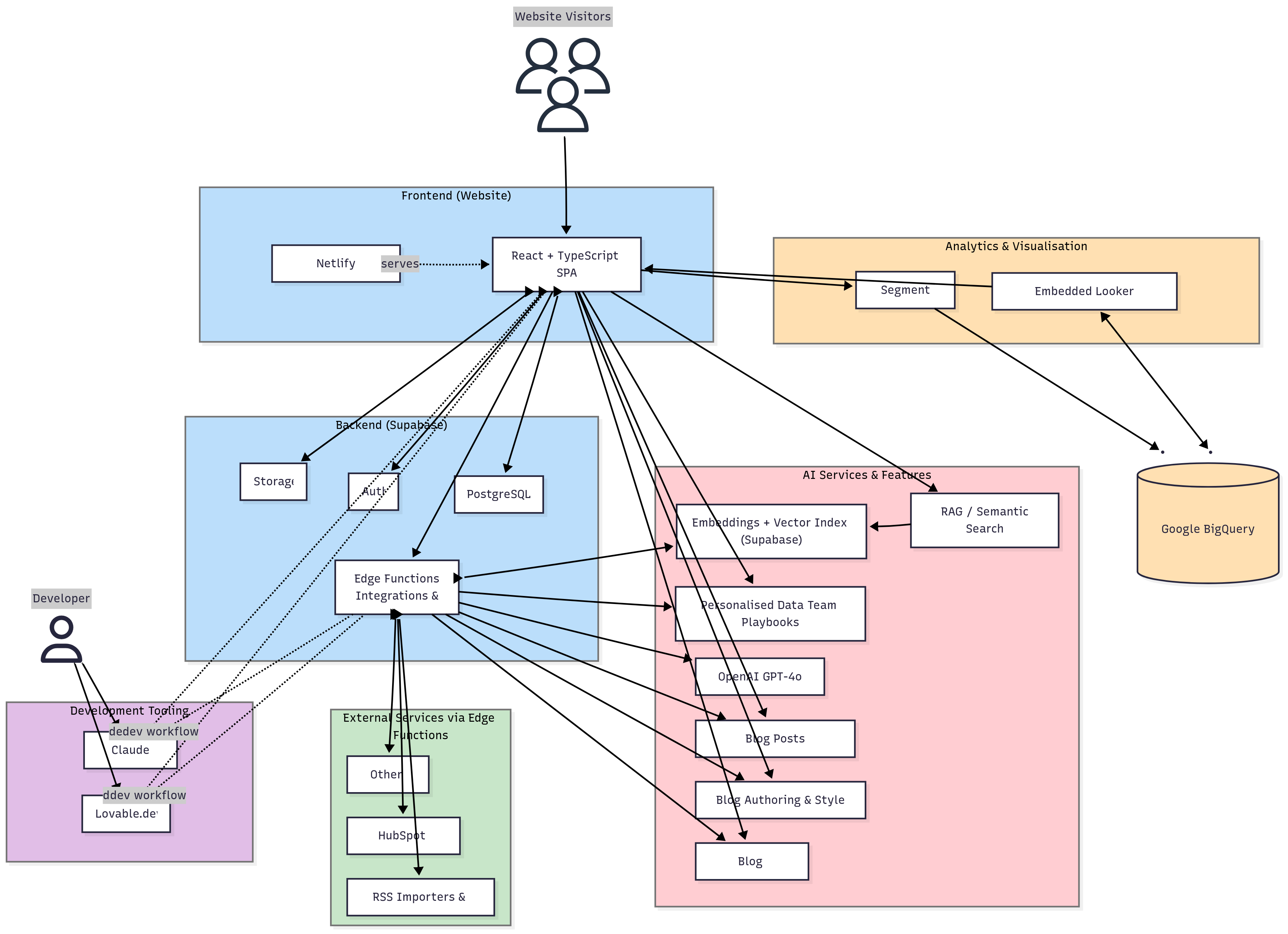
Opinionated, AI-Enabled & Modern: The Story Behind Rittman Analytics’ New Website
Aug 29, 2025
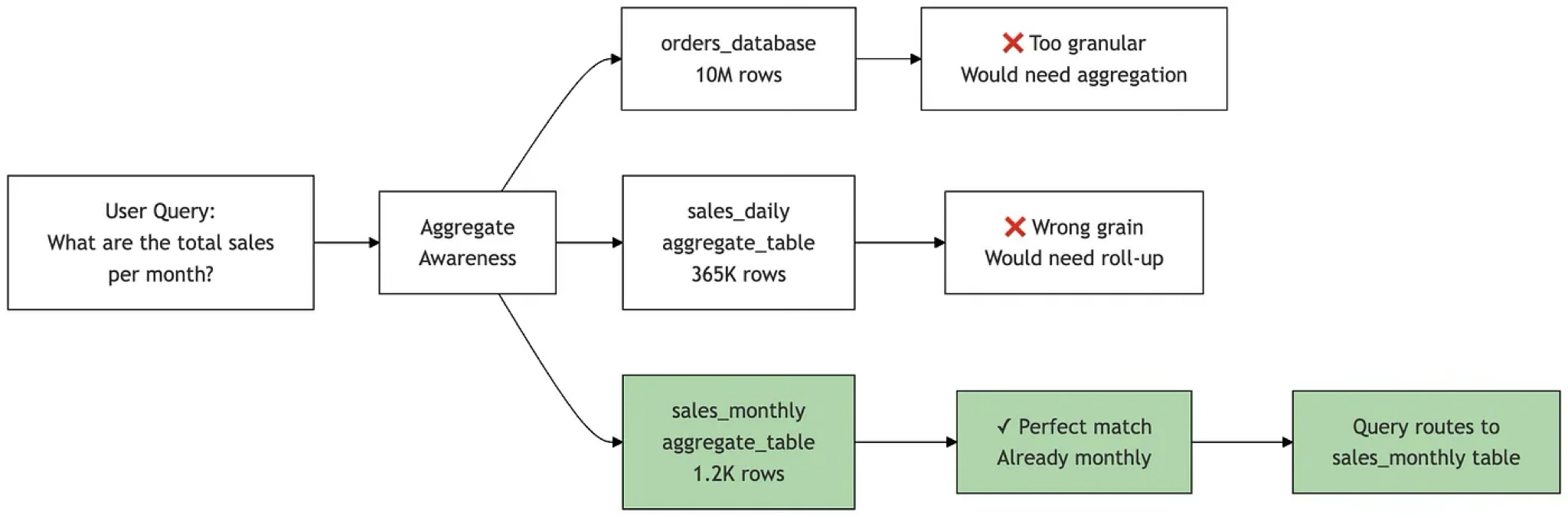
Adventures in Aggregate Awareness (and Level-Specific Measures) with Looker
Aug 25, 2025

When Your Talented Data Team is Stuck in Second-Gear
Jul 30, 2025
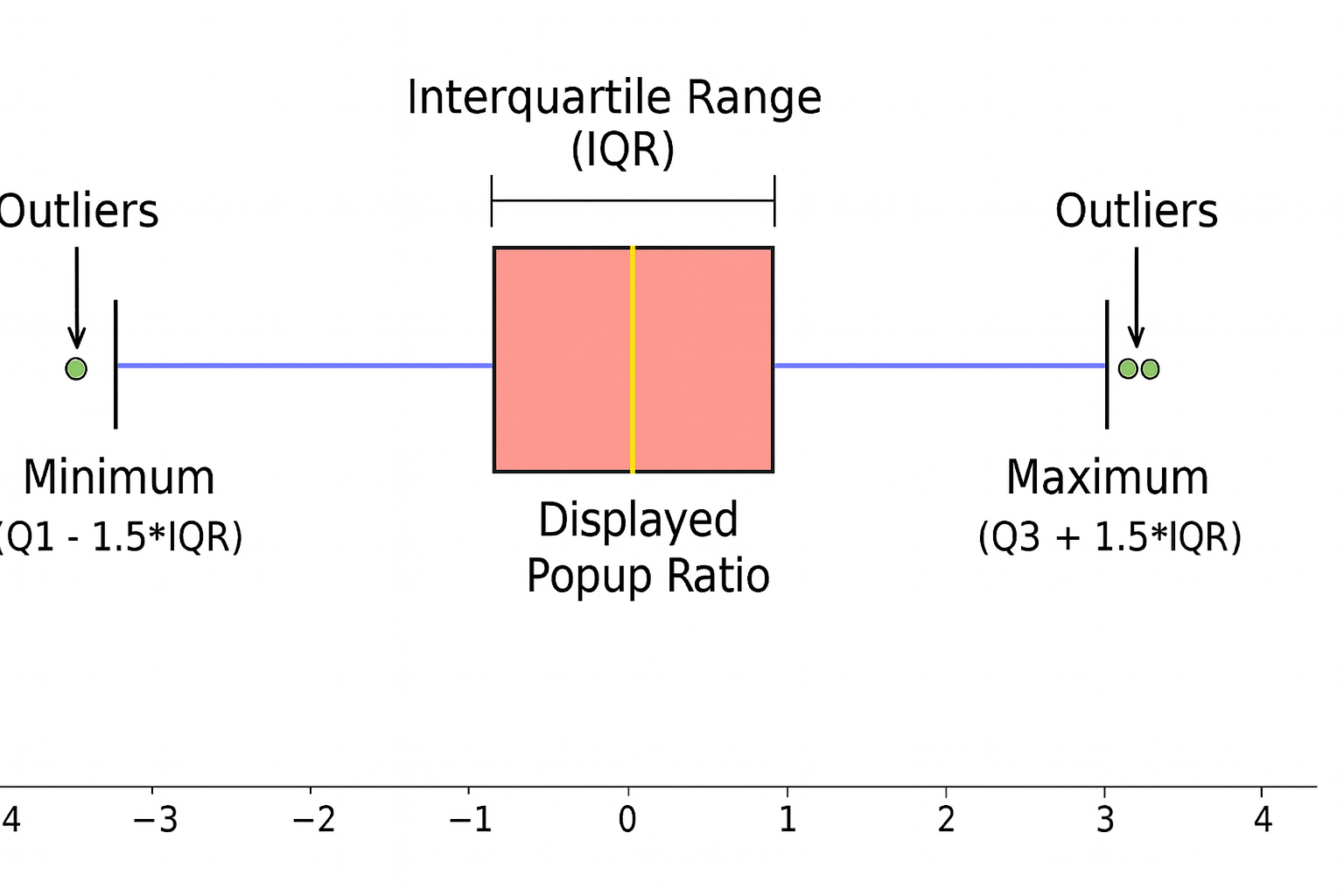
IQR-Based Website Event Anomaly Detection using Looker and Google BigQuery — Rittman Analytics
Jul 28, 2025

Integrating Looker and LangChain with langchain-looker-agent
Jun 2, 2025
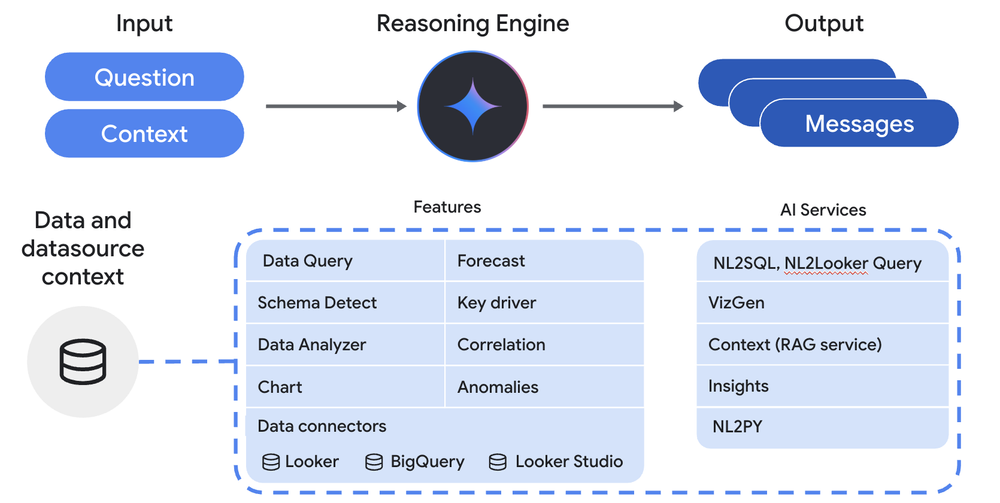
Introducing Conversational Analytics, Data Agents and Code Interpreter in Looker and Looker Studio
May 11, 2025

London Looker Meetup - May 8th 2025 - Registration Open & Call for Speakers!
Mar 31, 2025

Drill to Detail Podcast Transcripts & Gen AI Insights Now Available, Powered by OpenAI Whisper API & BigQuery Colab Notebooks
Feb 14, 2025

How Rittman Analytics Automates Project RAG Status Reporting using Vertex AI, DocumentAI, BigQuery & Looker
Jan 29, 2025

Deploying Maxwell’s Demon: QA Automation In Droughty
Jan 20, 2025
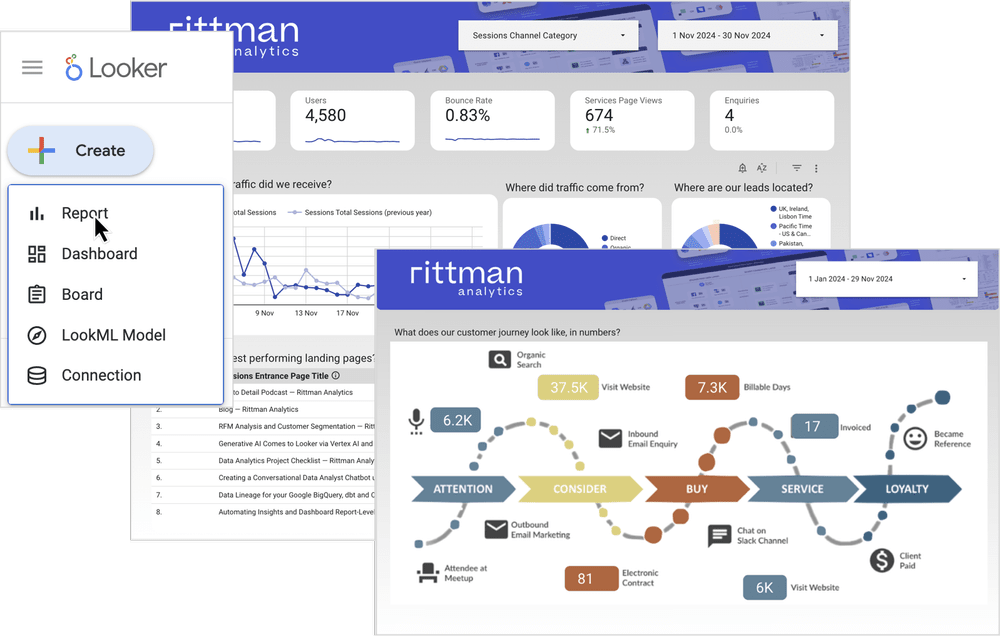
Previewing Studio in Looker, the (Eventual) Future of Self-Service Reporting for Looker
Dec 1, 2024
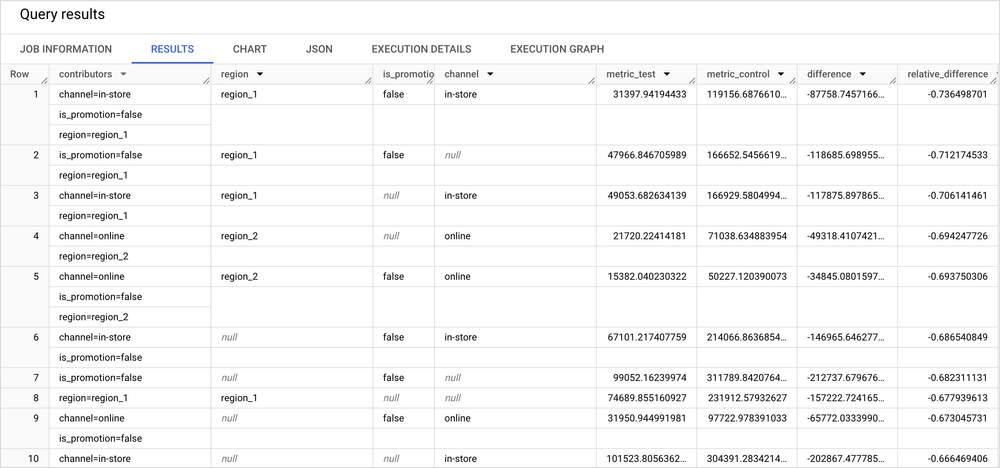
Discover the Underlying Drivers of Multichannel Retail Sales Performance with BigQuery BQML Contribution Analysis and Looker Studio
Nov 11, 2024

Coalesce 2024 and the Launch of dbt’s Visual Editing Experience
Oct 11, 2024

See you at Coalesce 2024 in Las Vegas, October 7th – 10th 2024
Oct 3, 2024

Creating a Self-Learning Data Analytics SQL Chatbot using LangChain, RAG, Open AI and Google BigQuery Vector Store
Sep 30, 2024
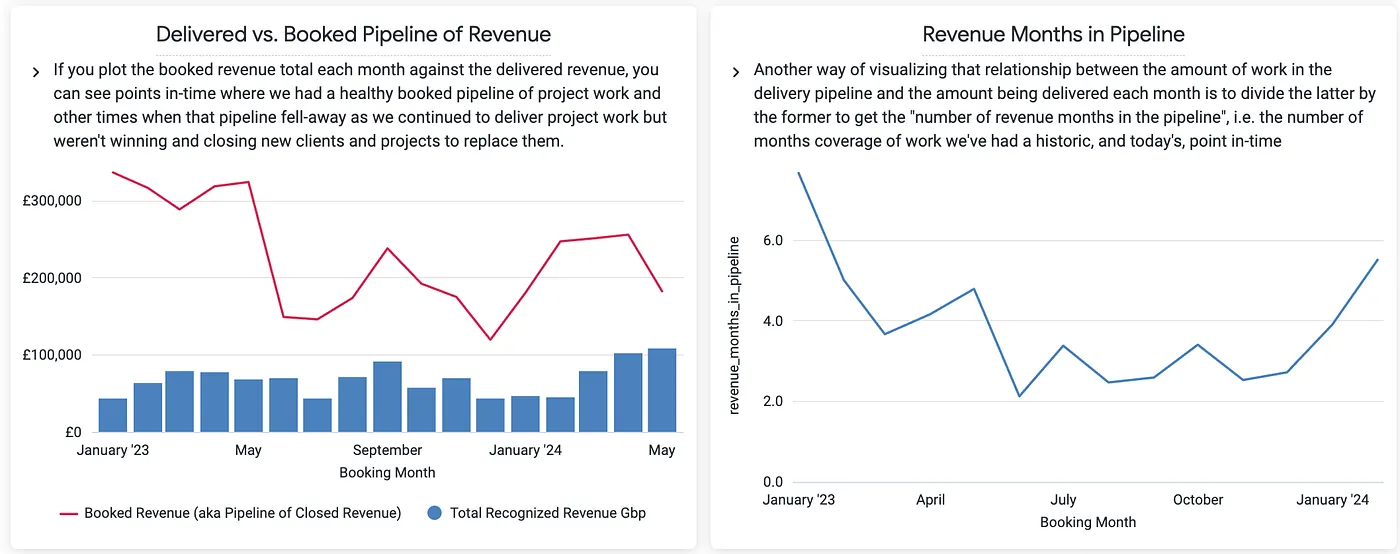
Analyzing your Historical Revenue & Sales Pipeline Over-Time using Google BigQuery, Fivetran, Stitch and Looker | by Mark Rittman | Rittman Analytics Blog
Sep 23, 2024

Analyzing Your Historical Revenue & Sales Pipeline Over Time using Google BigQuery, Fivetran, Stitch and Looker
Sep 23, 2024

How Rittman Analytics Automates our Profit & Loss Reporting and Commentary using VertexAI Gemini 1.5-FLASH and Google BigQuery
Sep 17, 2024
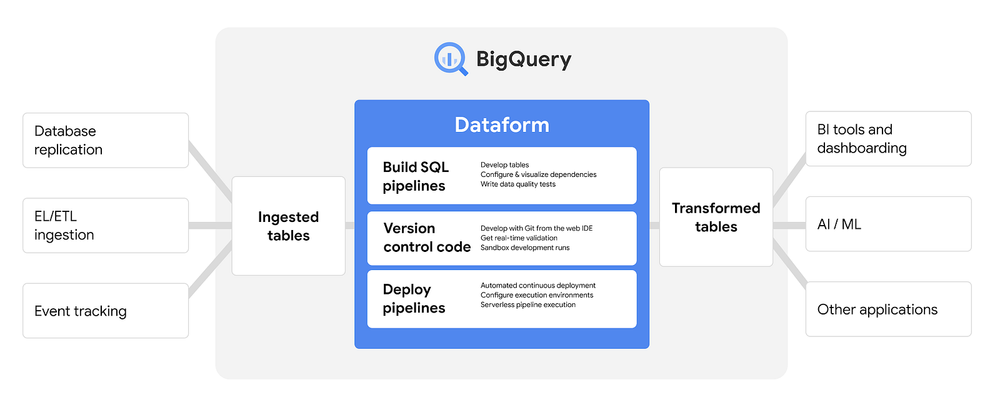
Announcing our Automated dbt-to-Dataform Migration Tool, Powered by Open AI
Aug 1, 2024

Recent Posts
One Person Many Roles: Designing a Unified Person Dimension in Google BigQuery
Jan 26
Why We’ve Tried to Replace Data Analytics Developers Every Decade Since 1974
Jan 19
How Rittman Analytics uses AI-Augmented Project Delivery to Provide Value to Users, Faster
Jan 19
Rittman Analytics 2025 Wrapped : A Year of Platforms, People and High-Performing Data Teams
Jan 19
You Probably Don’t Need an RFP
Jan 19
Claude Meets Looker: Building Smarter, Connected Analytics with Google’s MCP Toolbox
Dec 8
From Prompts to Skills: Automating Financial and KPI Analysis in Looker with Claude Skills and MCP Toolbox
Dec 8
An Homage to Oracle Warehouse Builder, 25 Years Ahead of Its Time
Dec 8
Google Integrates Spectacles into Looker for Continuous Integration & Regression Testing
Sep 8
How Rittman Analytics Does Financial Analytics using Looker, Fivetran and Google BigQuery
Sep 7
RSS Feed
Published Year
2026
(5)
2025
(16)
2024
(22)
2023
(9)
2022
(6)
2021
(6)
2020
(3)
2019
(1)
2018
(2)
2017
(2)
2016
(9)
Tag Cloud
Modern Data Stack (55)Data Engineering (51)BigQuery (35)Looker (34)Analytics Engineering (30)Business Intelligence (BI) (23)dbt (21)Data Quality (13)Google Cloud (GCP) (12)Generative AI (7)Automation (6)Fivetran (5)Dashboards (5)Oracle (5)single-post (4)Semantic Layer (3)Financial Analytics (3)Looker Studio (3)Cube.js (3)LangChain (1)OpenAI (1)Embedded Analytics (1)Vertex AI (1)LLMs (Large Language Models) (1)
Categories
Data Platform Implementation
41
Generative AI Solutions
17
Expert Services
8
Data Strategy Framework
6
Data Team Modernisation
5
Embedded Analytics
4