Bringing dbt and Analytics Engineering to Oracle Autonomous Data Warehouse — Rittman Analytics
dbt (Data Build Tool) is an open source command-line tool for managing and automating data transformation workflows. It enables a standardised, modular approach to building analytics code and is typically used as part of an increasingly popular method of developing data warehouses and data platforms called analytics engineering.
The analytics engineering approach combines software engineering principles with analytics to create more maintainable, trustworthy data pipelines built on transformation logic that is modular, scalable, tested, and well-documented.
With dbt, analytics code progresses from messy, ad hoc scripts to structured engineering workflows developed using a software development lifecycle. In this post, I’ll introduce dbt, explain its benefits for Oracle Database and Autonomous Data Warehouse developers and walk through getting started with dbt and the new dbt-oracle adapter.
What is dbt?
ELT (Extract, Load, Transform) is a modern data warehousing pattern very familiar to Oracle data warehouse developers where raw data is first extracted and loaded into the target warehouse, then transformed within the warehouse itself.
This is where dbt comes in — it provides the “T” for managing transformations in ELT, with the E (extract) and L (load) typically handled by services such as Fivetran, Airbyte or Stitch.
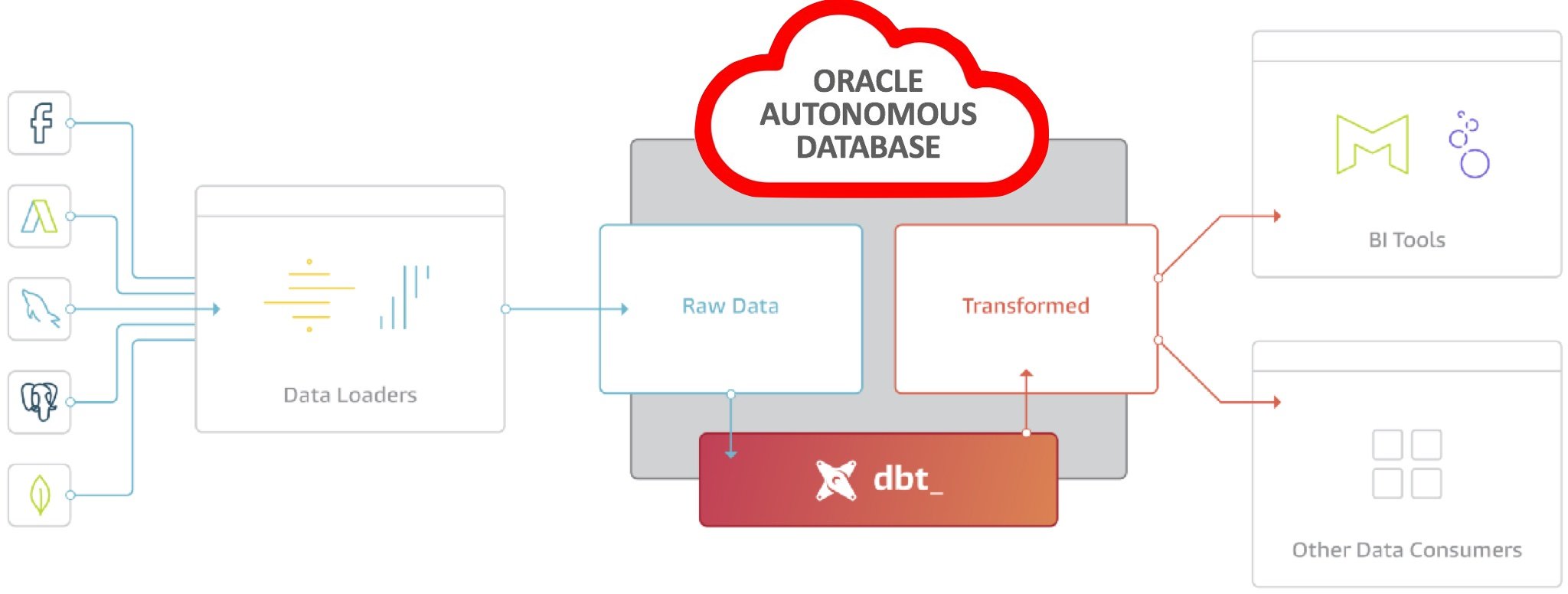
Originally developed to help data analysts within the VC-backed startup world develop production-ready data transformation code for Amazon Redshift and other cloud data warehouses, dbt is now more of an ecosystem than single tool and comprises of:
An open source core (dbt Core), originally developed by Fishtown Analytics (now dbt Labs) that you run from the command-line and can schedule using cron jobs or orchestrators such as Dagster
a commercial SaaS service (dbt Cloud) that provides features for developing, testing, scheduling and investigating data models
community-provided utilities and content packages (such as our RA Attribution package for multi-touch marketing attribution) along with official and related Slack groups
Key capabilities of dbt include:
Dependency management — dbt handles model dependencies automatically
Testing — add tests to models to ensure data quality
Refactoring — easily refactor models without breaking dependencies
Documentation — auto-generate docs for all models in a project
CI/CD Integration — build, test, and deploy projects on every code change
Whereas tools such as Oracle Data Integrator (ODI) and Oracle Warehouse Builder provide a visual, GUI-based mapping interface for designing data flows, dbt instead takes a code-centric approach with transformations encapsulated in modular SQL SELECT statements called “models”, either written and run using a text editor or tool such as Microsoft VS Code.
Developing transformation logic using a GUI has the benefit of opening-up this task to a wider audience, but when the business requires complex data transformations such an approach can become unwieldy.
More of a concern though is the ungoverned shadow SQL or Python code that drag-and-drop tool users end-up adding to their visual transformation nodes, making it hard to track changes and ensure those transformations and embedded are tested and reliable in a scalable and automated way.
A key difference between ODI and dbt is therefore in its approach to modularity and reusable transformation logic. With ODI, code reuse is achieved by copying and modifying mappings across projects; dbt, however achieves this through the use of those modular, configurable SQL models that can be packaged up into shared libraries and invoked repeatedly.
Also, crucially, dbt models exist as simple SQL files making them straightforward to version control via Git. ODI’s visual mappings are stored within its repository, requiring use of ODI lifecycle tools.
With dbt, developers can utilize the full power of Git for branching strategies, pull requests, and decentralized development.
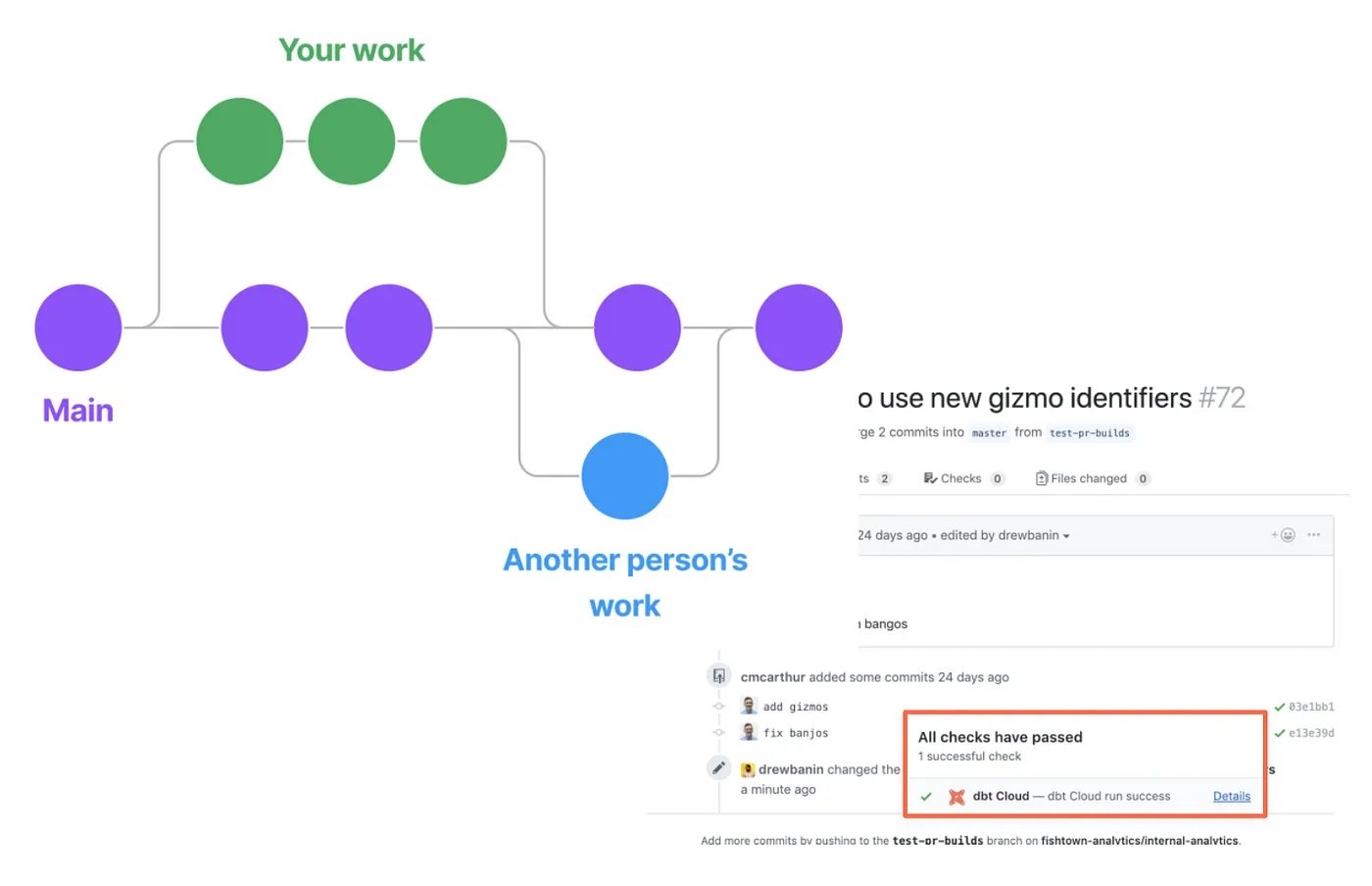
dbt models also provide visibility into history and differences between versions.
Getting Started with dbt-oracle
The dbt-oracle adapter (originally created by Indicium, now supported and maintained directly by Oracle) is a python package that contains the core dbt libraries together with an adapter for connecting to on-premises and cloud Oracle databases. This, along with an install of Python 3 and the oracledb client drivers package are what’s required to install dbt on your Mac, for example.
python3 -m venv dbt-oracle-venv source dbt-oracle-venv/bin/activate pip install --upgrade pip python -m pip install oracledb --upgrade python -m pip install dbt-oracle
The dbt-oracle Github repo at https://github.com/oracle/dbt-oracle contains a demo dbt package that transforms data from the SH (Sales History) example schema shipped with all Oracle database versions.
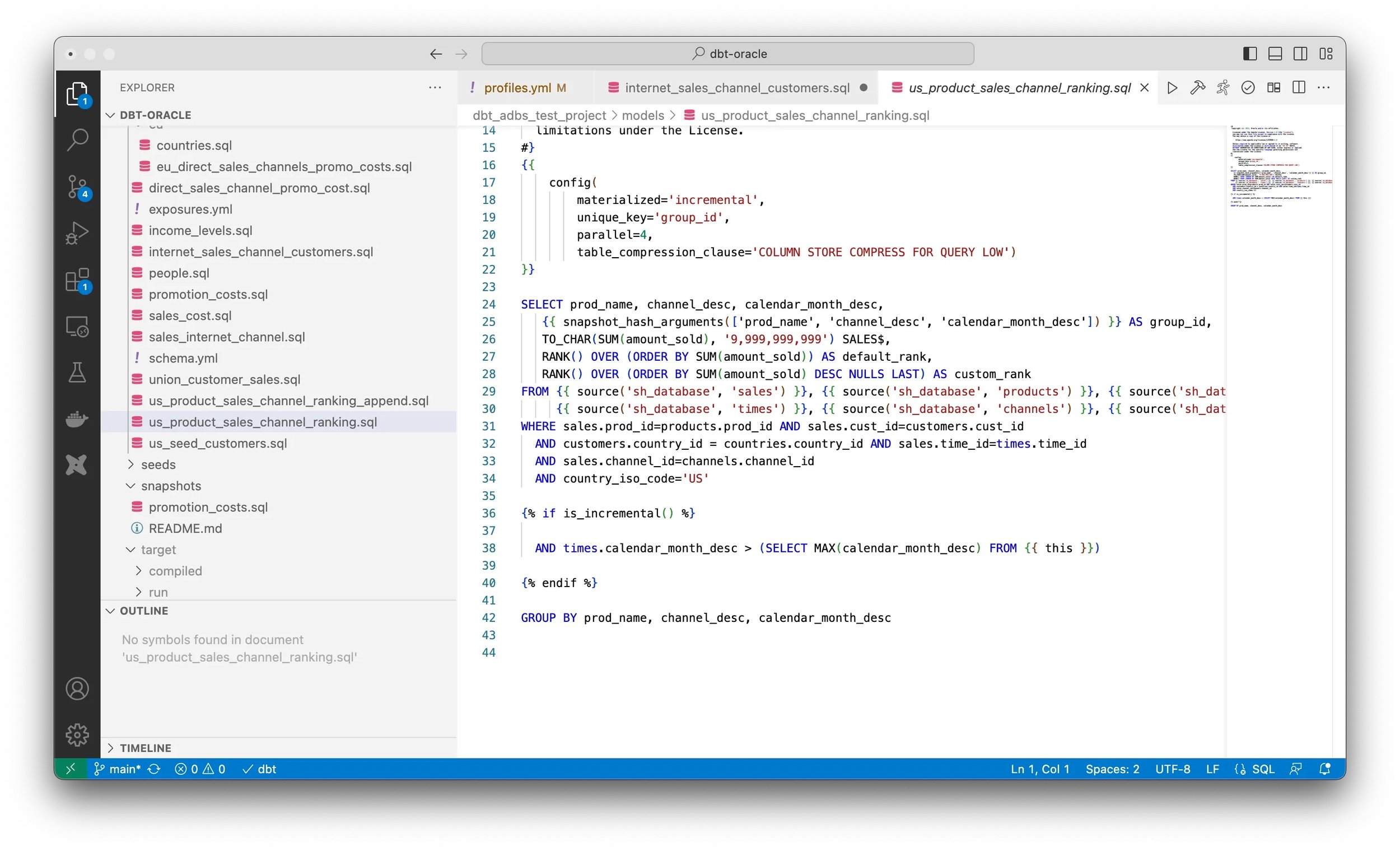
Looking at an example dbt model within that demo package, you can see examples of model configuration settings, references to other tables in the form of sources and some Jinja templating code that adds a further WHERE clause to the SQL statement when the model is compiled in incremental load mode.
{{config(materialized='incremental', unique_key='group_id')}} WITH direct_sales_promo_cost AS ( SELECT s.prod_id, s.quantity_sold, s.amount_sold, s.time_id, c.channel_desc, p.promo_name, p.promo_cost, {{ hash_arguments(['s.prod_id', 's.quantity_sold', 's.time_id', 'p.promo_name']) }} AS group_id FROM {{ source('sh_database', 'sales') }} s, {{ source('sh_database', 'promotions') }} p, {{ source('sh_database', 'channels') }} c WHERE s.channel_id = 3 AND s.promo_id = p.promo_id AND s.channel_id = c.channel_id {% if is_incremental() %} AND s.time_id > (SELECT MAX(time_id) FROM {{ this }}) {% endif %} ) SELECT * FROM direct_sales_promo_costOther model definitions use ref() Jinja functions instead of table names to define dependencies between tables in a transformation DAG, and use Oracle-specific configuration settings to tell dbt how specifically to materialize the database object that is the result of compiling this particular model.
{{config( materialized='table', parallel=4, table_compression_clause='COLUMN STORE COMPRESS FOR QUERY' ) }} select c.cust_id, c.cust_first_name, c.cust_last_name, t.country_iso_code, t.country_name, t.country_region from {{ ref('sales_internet_channel') }} s, {{ source('sh_database', 'countries') }} t, {{ source('sh_database', 'customers') }} c WHERE s.cust_id = c.cust_id AND c.country_id = t.country_iddbt Core data source connections are defined using a configuration file in YAML format stored by default at $HOME/.dbt/profiles.yml, outside of the git repository files so database credentials don’t get published with your code by accident.
dbt_test: target: dev outputs: dev: type: oracle user: MARK_DBT pass: ***** protocol: "tcps" host: adb.uk-london-1.oraclecloud.com port: 1522 service: g71ab9f09757846_radevelopmentadw_high.adb.oraclecloud.com schema: MARK_DBT retry_count: 1 retry_delay: 5 shardingkey: - skey supershardingkey: - sskey cclass: CONNECTIVITY_CLASS purity: self threads: 1
There are various ways that dbt can connect to an Oracle database; using thin or thick drivers from the python-oracledb Oracle client libraries package along with the choice of either TLS (Transport Layer Security) or mutual TLS (mTLS) when connecting to Oracle Autonomous Data Warehouse or Autonomous Transaction Processing.
I used the thin client mode and was able to connect to Oracle Autonomous Data Warehouse Cloud without using a wallet file, using just my database username, password and host/port/service name.
dbt Core packages are run from the command-line and when executed, compile your SQL and Jinja model code into SQL SELECT and MERGE statements that transforms, tests and runs utilities to transform your data within the Oracle database.
(dbt-oracle-venv) markrittman@marks-imac-4 dbt_adbs_test_project % dbt build 21:47:47 Running with dbt=1.5.3 21:47:47 oracle adapter: Running in thin mode 21:47:47 Registered adapter: oracle=1.5.3 21:47:47 Found 17 models, 10 tests, 1 snapshot, 1 analysis, 637 macros, 3 operations, 1 seed file, 8 sources, 2 exposures, 0 metrics, 0 groups 21:47:47 21:47:50 21:47:50 Running 1 on-run-start hook 21:47:50 1 of 1 START hook: dbt_adbs_test_project.on-run-start.0 ........................ [RUN] 21:47:50 1 of 1 OK hook: dbt_adbs_test_project.on-run-start.0 ........................... [OK in 0.03s] 21:47:50 21:47:50 Concurrency: 1 threads (target='dev') 21:47:50 21:47:50 1 of 28 START sql table model MARK_DBT.countries ............................... [RUN] 21:47:52 1 of 28 OK created sql table model MARK_DBT.countries .......................... [OK in 1.30s] 21:47:52 2 of 28 START sql view model MARK_DBT.direct_sales_channel_promo_cost .......... [RUN] 21:47:53 2 of 28 OK created sql view model MARK_DBT.direct_sales_channel_promo_cost ..... [OK in 0.88s] 21:47:53 3 of 28 START sql table model MARK_DBT.promotion_costs ......................... [RUN] 21:47:54 3 of 28 OK created sql table model MARK_DBT.promotion_costs .................... [OK in 1.30s] 21:47:54 4 of 28 START sql table model MARK_DBT.promotion_costs_for_direct_sales_channel [RUN] 21:47:56 4 of 28 OK created sql table model MARK_DBT.promotion_costs_for_direct_sales_channel [OK in 2.49s] 21:47:56 5 of 28 START sql incremental model MARK_DBT.promotion_costs_for_direct_sales_channel_incr_insert [RUN] 21:47:59 5 of 28 OK created sql incremental model MARK_DBT.promotion_costs_for_direct_sales_channel_incr_insert [OK in 2.37s] 21:47:59 6 of 28 START sql incremental model MARK_DBT.promotion_costs_for_direct_sales_channel_incr_merge [RUN] 21:48:00 6 of 28 OK created sql incremental model MARK_DBT.promotion_costs_for_direct_sales_channel_incr_merge [OK in 1.56s] 21:48:00 7 of 28 START sql incremental model MARK_DBT.promotion_costs_for_direct_sales_channel_incr_merge_unique_keys [RUN] 21:48:02 7 of 28 OK created sql incremental model MARK_DBT.promotion_costs_for_direct_sales_channel_incr_merge_unique_keys [OK in 1.78s] 21:48:02 8 of 28 START sql table model MARK_DBT.sales_cost .............................. [RUN] 21:48:04 8 of 28 OK created sql table model MARK_DBT.sales_cost ......................... [OK in 1.64s] 21:48:04 9 of 28 START sql table model MARK_DBT.sales_internet_channel .................. [RUN] 21:48:06 9 of 28 OK created sql table model MARK_DBT.sales_internet_channel ............. [OK in 2.20s] 21:48:06 10 of 28 START sql table model MARK_DBT.union_customer_sales ................... [RUN] 21:48:12 10 of 28 OK created sql table model MARK_DBT.union_customer_sales .............. [OK in 6.14s] 21:48:12 11 of 28 START sql incremental model MARK_DBT.us_product_sales_channel_ranking . [RUN] 21:48:14 11 of 28 OK created sql incremental model MARK_DBT.us_product_sales_channel_ranking [OK in 2.20s] 21:48:14 12 of 28 START sql incremental model MARK_DBT.us_product_sales_channel_ranking_append [RUN] 21:48:17 12 of 28 OK created sql incremental model MARK_DBT.us_product_sales_channel_ranking_append [OK in 2.62s] 21:48:17 13 of 28 START seed file MARK_DBT.seed ......................................... [RUN] 21:48:18 13 of 28 OK loaded seed file MARK_DBT.seed ..................................... [INSERT 5 in 0.96s] 21:48:18 14 of 28 START test dbt_constraints_primary_key_countries_country_id ........... [RUN] 21:48:19 14 of 28 PASS dbt_constraints_primary_key_countries_country_id ................. [PASS in 1.50s] 21:48:19 15 of 28 START test not_null_countries_country_id .............................. [RUN] 21:48:21 15 of 28 PASS not_null_countries_country_id .................................... [PASS in 1.14s] 21:48:21 16 of 28 START test unique_countries_country_id ................................ [RUN] 21:48:21 16 of 28 PASS unique_countries_country_id ...................................... [PASS in 0.62s] 21:48:21 17 of 28 START sql view model MARK_DBT.us_seed_customers ....................... [RUN] 21:48:22 17 of 28 OK created sql view model MARK_DBT.us_seed_customers .................. [OK in 0.90s] 21:48:22 18 of 28 START snapshot MARK_DBT.promotion_costs_snapshot ...................... [RUN] 21:48:24 18 of 28 OK snapshotted MARK_DBT.promotion_costs_snapshot ...................... [success in 2.28s] 21:48:24 19 of 28 START sql table model MARK_DBT.internet_sales_channel_customers ....... [RUN] 21:48:29 19 of 28 OK created sql table model MARK_DBT.internet_sales_channel_customers .. [OK in 4.41s] 21:48:29 20 of 28 START sql table model MARK_DBT.people ................................. [RUN] 21:48:32 20 of 28 OK created sql table model MARK_DBT.people ............................ [OK in 2.86s] 21:48:32 21 of 28 START sql table model MARK_DBT.eu_direct_sales_channels_promo_costs ... [RUN] 21:48:34 21 of 28 OK created sql table model MARK_DBT.eu_direct_sales_channels_promo_costs [OK in 1.92s] 21:48:34 22 of 28 START test accepted_values_people_gender__Male__Female ................ [RUN] 21:48:35 22 of 28 PASS accepted_values_people_gender__Male__Female ...................... [PASS in 1.13s] 21:48:35 23 of 28 START test dbt_constraints_primary_key_people_id ...................... [RUN] 21:48:36 23 of 28 PASS dbt_constraints_primary_key_people_id ............................ [PASS in 0.85s] 21:48:36 24 of 28 START test not_null_people_id ......................................... [RUN] 21:48:36 24 of 28 PASS not_null_people_id ............................................... [PASS in 0.74s] 21:48:36 25 of 28 START test test_count_employees ....................................... [RUN] 21:48:37 25 of 28 PASS test_count_employees ............................................. [PASS in 0.96s] 21:48:37 26 of 28 START test unique_people_id ........................................... [RUN] 21:48:38 26 of 28 PASS unique_people_id ................................................. [PASS in 1.05s] 21:48:38 27 of 28 START test dbt_constraints_foreign_key_eu_direct_sales_channels_promo_costs_country_id__country_id__ref_countries_ [RUN] 21:48:39 27 of 28 PASS dbt_constraints_foreign_key_eu_direct_sales_channels_promo_costs_country_id__country_id__ref_countries_ [PASS in 0.93s] 21:48:39 28 of 28 START test relationships_eu_direct_sales_channels_promo_costs_country_id__country_id__ref_countries_ [RUN] 21:48:40 28 of 28 PASS relationships_eu_direct_sales_channels_promo_costs_country_id__country_id__ref_countries_ [PASS in 0.75s] 21:48:41 21:48:41 Running 2 on-run-end hooks 21:48:41 1 of 2 START hook: dbt_adbs_test_project.on-run-end.0 .......................... [RUN] 21:48:41 1 of 2 OK hook: dbt_adbs_test_project.on-run-end.0 ............................. [OK in 0.03s] 21:48:41 Running dbt Constraints 21:48:45 Creating primary key: COUNTRIES_COUNTRY_ID_PK 21:48:49 Creating primary key: PEOPLE_ID_PK 21:48:53 Creating foreign key: FK_2419558567 referencing countries ['country_id'] 21:48:54 Finished dbt Constraints 21:48:54 2 of 2 START hook: dbt_constraints.on-run-end.0 ................................ [RUN] 21:48:54 2 of 2 OK hook: dbt_constraints.on-run-end.0 ................................... [OK in 0.00s] 21:48:54 21:48:54 21:48:54 Finished running 9 table models, 2 view models, 5 incremental models, 1 seed, 10 tests, 1 snapshot, 3 hooks in 0 hours 1 minutes and 7.14 seconds (67.14s). 21:48:54 21:48:54 Completed successfully 21:48:54 21:48:54 Done. PASS=28 WARN=0 ERROR=0 SKIP=0 TOTAL=28
dbt packages typically include descriptions for fields, schema definitions and other metadata that, together with the DAG dependency graph defined by all of the ref() and source() definitions within your models can be served-up from the command line using a built-in webserver, like this:
(dbt-oracle-venv) markrittman@marks-imac-4 dbt_adbs_test_project % dbt docs generate 21:54:57 Running with dbt=1.5.3 21:54:57 oracle adapter: Running in thin mode 21:54:57 Registered adapter: oracle=1.5.3 21:54:57 Found 17 models, 10 tests, 1 snapshot, 1 analysis, 637 macros, 3 operations, 1 seed file, 8 sources, 2 exposures, 0 metrics, 0 groups 21:54:57 21:55:00 Concurrency: 1 threads (target='dev') 21:55:00 21:55:03 Running dbt Constraints 21:55:03 Finished dbt Constraints 21:55:04 Building catalog 21:56:12 Catalog written to /Users/markrittman/prod/dbt-oracle/dbt_adbs_test_project/target/catalog.json (dbt-oracle-venv) markrittman@marks-imac-4 dbt_adbs_test_project % dbt docs serve 22:06:41 Running with dbt=1.5.3 22:06:41 oracle adapter: Running in thin mode Serving docs at 8080 To access from your browser, navigate to: http://localhost:8080 Press Ctrl+C to exit. 127.0.0.1 - - [06/Sep/2023 23:06:41] "GET / HTTP/1.1" 200 - 127.0.0.1 - - [06/Sep/2023 23:06:42] "GET /manifest.json?cb=1694038002092 HTTP/1.1" 200 - 127.0.0.1 - - [06/Sep/2023 23:06:42] "GET /catalog.json?cb=1694038002092 HTTP/1.1" 200 -
and then visualized as a data dictionary portal and transformation dependency graph, like this:
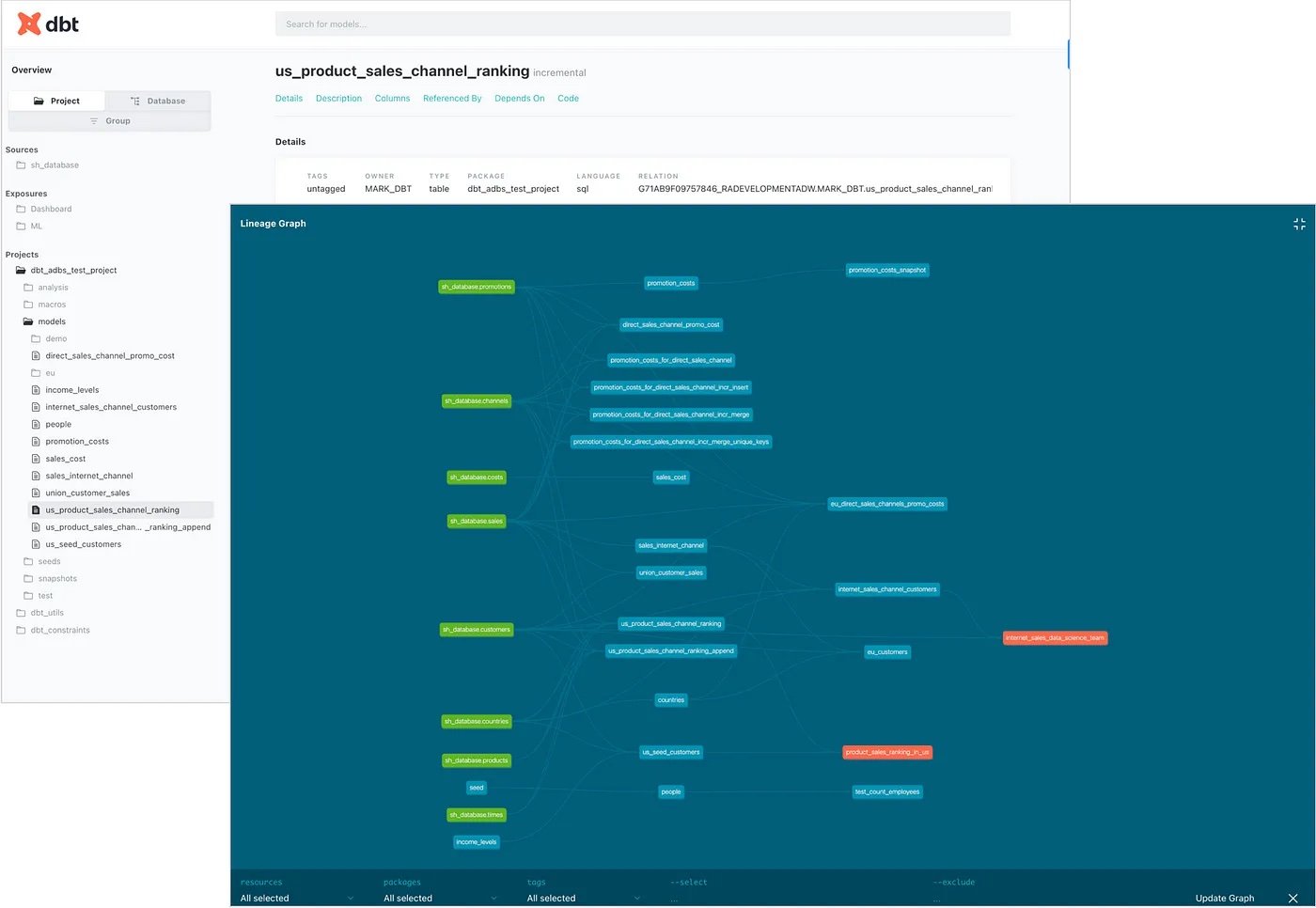
Interested? Find Out More!
Rittman Analytics is a boutique data analytics consultancy that’s both an Oracle Partner with over 25 years experience working with Oracle technology and Oracle customers, and a long standing partner of dbt Labs, the software company that sponsors dbt Core development.
You can read more about our work with dbt on our blog, see examples of our dbt development approach in our Github repo and listen to episodes of our podcast, Drill to Detail, where we discuss dbt and the analytics engineering approach with one of dbt’s original authors, Tristan Handy.
If you’re looking for some help and assistance adopting dbt and the analytics engineering approach to data warehouse development, or to help build-out your analytics capabilities and data team using a modern, flexible and modular data stack, contact us now to organise a 100%-free, no-obligation call — we’d love to hear from you!
CEO of Rittman Analytics, host of the Drill to Detail Podcast, ex-product manager and twice company founder.
Recommended Posts

See you at Coalesce 2024 in Las Vegas, October 7th – 10th 2024
One Person Many Roles: Designing a Unified Person Dimension in Google BigQuery
Why We’ve Tried to Replace Data Analytics Developers Every Decade Since 1974
