Data Lineage for your Google BigQuery, dbt and Cloud Composer Data Pipelines using Dataplex and Data Catalog — Rittman Analytics
Google Cloud recently announced the general availability of Dataplex data lineage, a fully managed service that helps organizations understand how data is sourced and transformed within their Google Cloud environment.
Dataplex data lineage automatically tracks data movement across BigQuery, BigLake, Cloud Data Fusion (Preview), and Cloud Composer (Preview), eliminating the operational hassles associated with manual curation of lineage metadata.
Dataplex Data Lineage provides an interactive lineage graph within the Google Cloud Console Bigquery web UI that provides data observability by detailing “what happened” and “when it happened” for each lineage relationship, so that:
Data analysts can easily determine if a table originates from an authoritative source through self-service lineage lookup, fostering trust in the data.
Data engineers can reduce time spent on identifying and resolving data issues through root cause analysis enabled by operational metadata tracing lineage relationships
Data stewards and owners can leverage lineage as the foundation for data governance practices, enabling them to evaluate and enforce adherence to governance requirements, especially when tracking the movement of sensitive information.
So what is data lineage, and what is Google Cloud Dataplex?
Data lineage is a term used to describe the traceable path your data takes through its lifecycle from raw through to transformed and governed data via tools and services such as dbt Core and Cloud Composer.
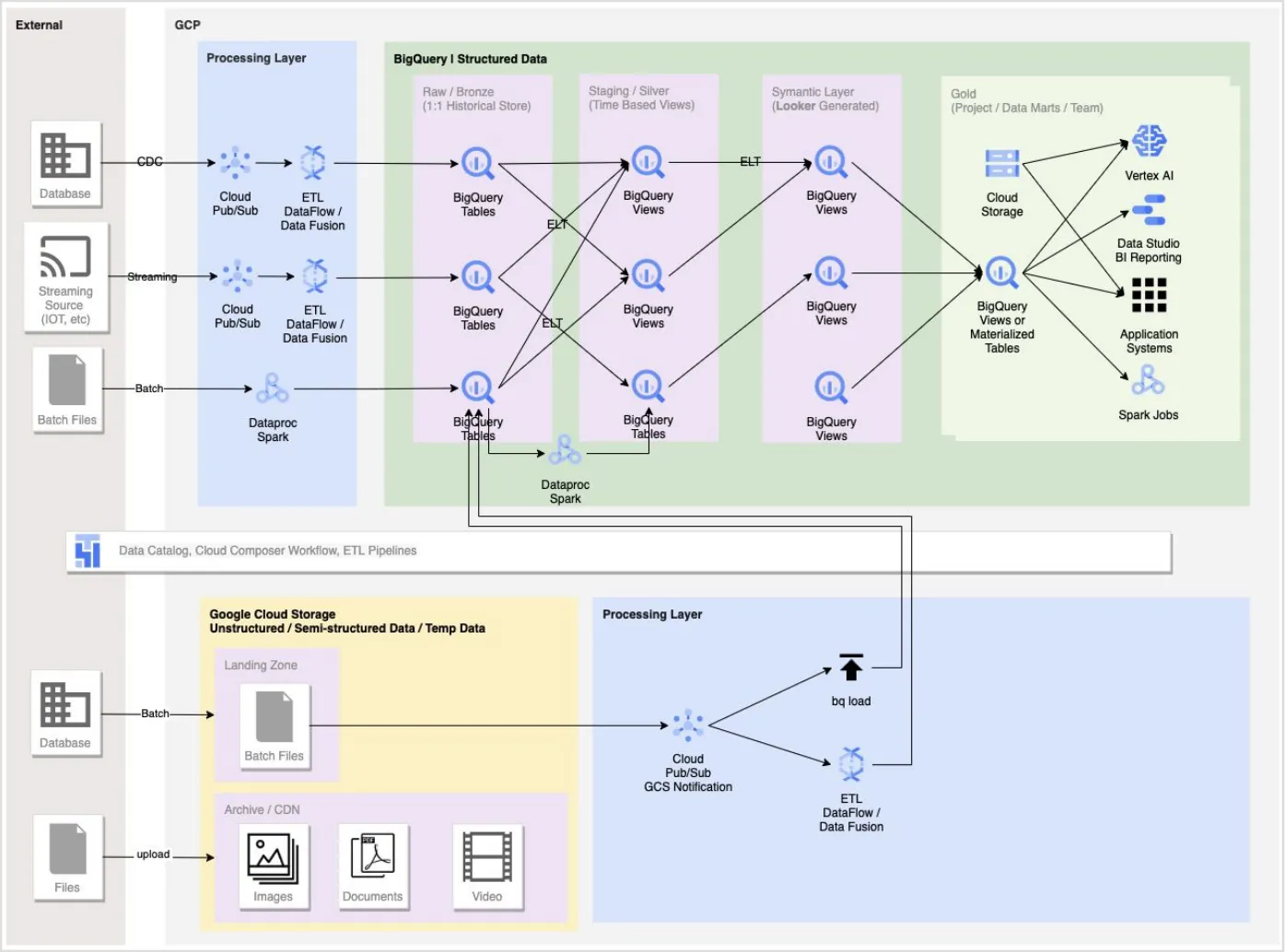
The diagram below shows a typical Medallion-style architecture implemented as a Google Cloud data lakehouse, showing the steps and stages data can go through before its presented to users or used, for example, as the source data for a Vertex AI large language model.
Understanding data lineage is crucial for BigQuery, dbt and AI developers for:
Impact Analysis: Identifing the tables impacted by changes in source data or transformations, allowing you to assess the potential downstream effects of modifications before implementation.
Troubleshooting: Quickly pinpoint the root cause of data quality issues by tracing the lineage back to the origin, streamlining debugging and increasing your developer efficiency
Regulatory Compliance: Demonstrating adherence to data governance regulations by providing a clear audit trail for data usage
Improved Development Efficiency: Understand data dependencies for efficient data pipeline development and maintenance. This is particularly beneficial for dbt developers, as lineage visualization helps them navigate complex data transformation workflows.
Data Lineage is a feature within another relatively new Google Cloud service called Dataplex, a unified data fabric service within Google Cloud.
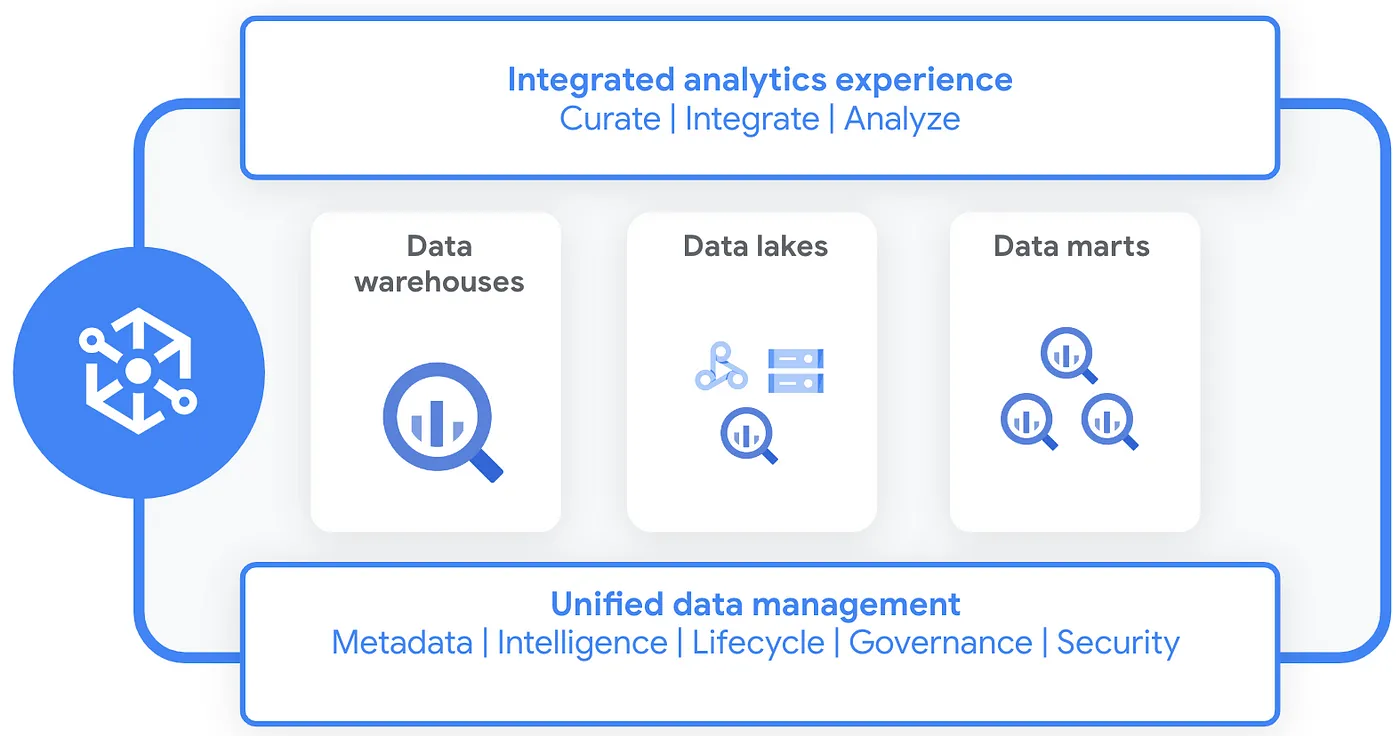
Dataplex is a central hub for managing and governing your data across Google Cloud projects and integrates with Google Cloud Data Catalog, a service that automatically discovers and catalogs your data assets.
Dataplex provides data lineage for your data warehouse objects by:
Automating lineage tracking: It automatically captures lineage information as data moves through your pipelines. This eliminates the need for manual configuration and streamlines lineage tracking.
Providing a unified view: Dataplex provides a centralized view of data lineage across all your data sources and pipelines. This holistic understanding allows you to see the big picture of your data flow.
Directly integrating with Data Fusion, DataProc and Cloud Composer: Data Fusion plug-ins enable you to track data lineage for Cloud Storage, Cloud SQL for MySQL and Spanner tables amongst other Google Cloud-native data assets along with third-party ones such as Oracle, SAP and PostgreSQL; Dataproc and Cloud Composer integrations extend your lineage graphs to include Apache Spark and Airflow tasks
Indirectly integrating with tools such as dbt Core by analyzing the trail of Google BigQuery DDL and DML statements those tools and services use to stage data and implement data transformations
To find-out more about Dataplex and experience it yourself with some hands-on labs, check-out Dataplex Quickstart for Cloud Architects and Engineers. Going back to our main topic of data lineage for Google BigQuery though, how does it actually work?
Data lineage tracking isn’t on by default in your Google BigQuery environment and has to be enabled by following these two steps:
Using the Google Cloud Console, select your project and then navigate to the APIs & Services section.
Enable the Data Lineage API for your project
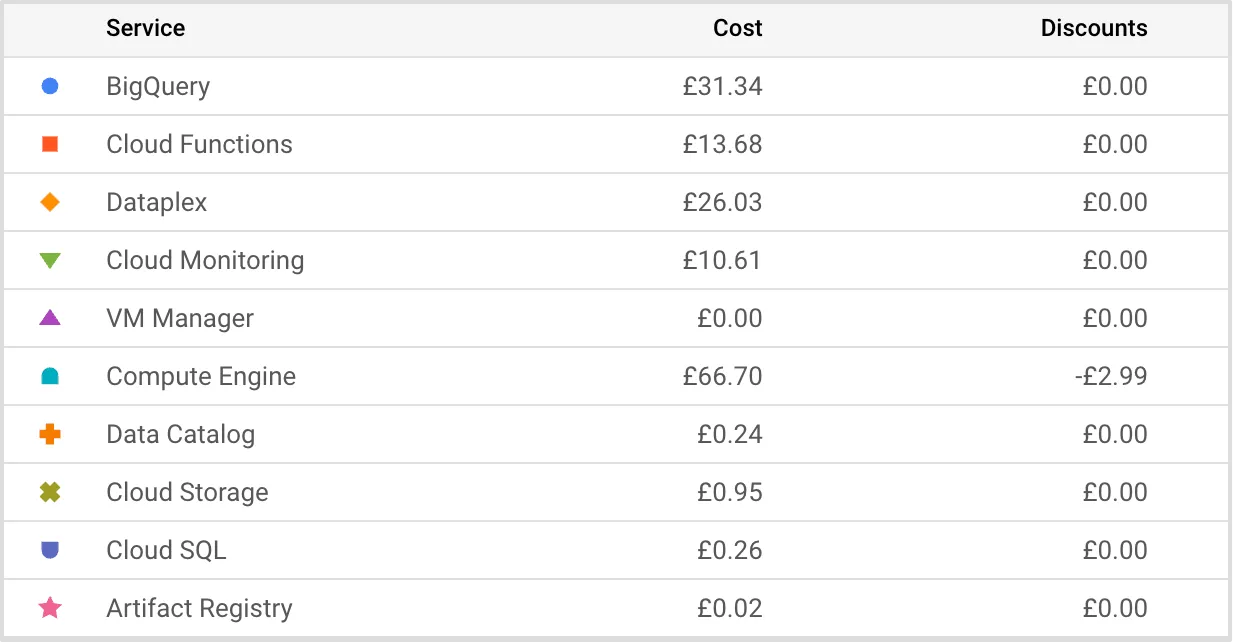
Note also that it’s not free to use; taking our own Google Cloud environment and looking at our billing account for the last seven days I can see that Dataplex cost nearly as much as what we were spending on BigQuery, neither of which were particularly expensive but worth noting regardless.
Data lineage is enabled on a per-project basis and after enabling the Data Lineage API, lineage information is automatically reported for the following BigQuery operations
Copy jobs
Load jobs (using Cloud Storage URI)
Query jobs with DDL statements (CREATE TABLE, CREATE VIEW, etc.)
Modifications to existing BigQuery tables using DML statements (SELECT, INSERT, UPDATE, DELETE, etc.)
Although dbt Core doesn’t itself integrate directly with Dataplex, the tables and other objects it creates in BigQuery along with the SQL transformations it implements as part of the CREATE TABLE AS... and MERGE INTO… DDL commands to create those objects are enough for Dataplex to stitch-together those objects’ data lineage, as you can see in the example below showing the lineage for one of our internal warehouse dimension tables:
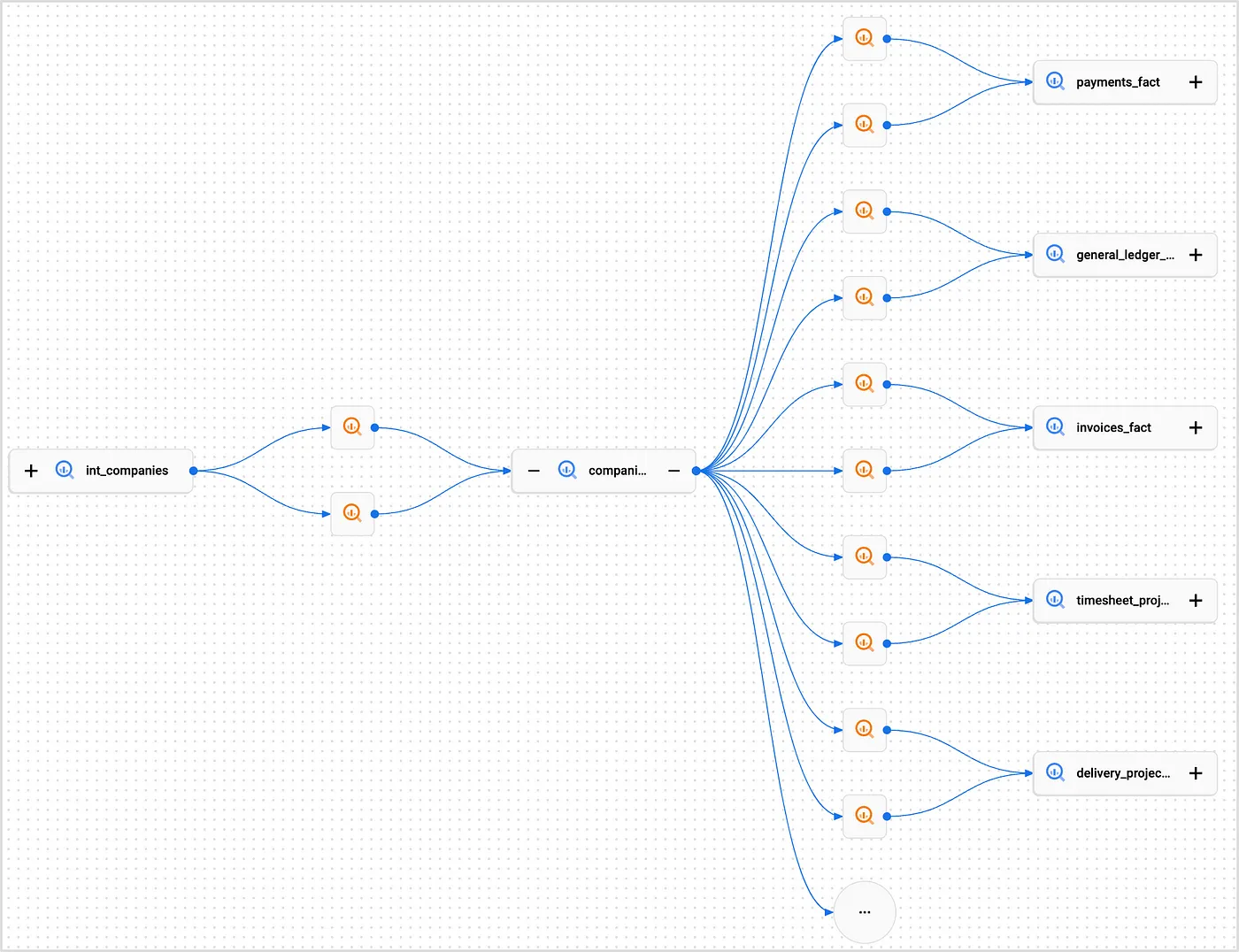
Clicking on the “+” icon on the left-hand side of the int_companies table expands the graph to show the sources for this “silver”-layer table, and I can see the SQL transformation that dbt generated to combine the target table’s sources together and deduplicate their contents.
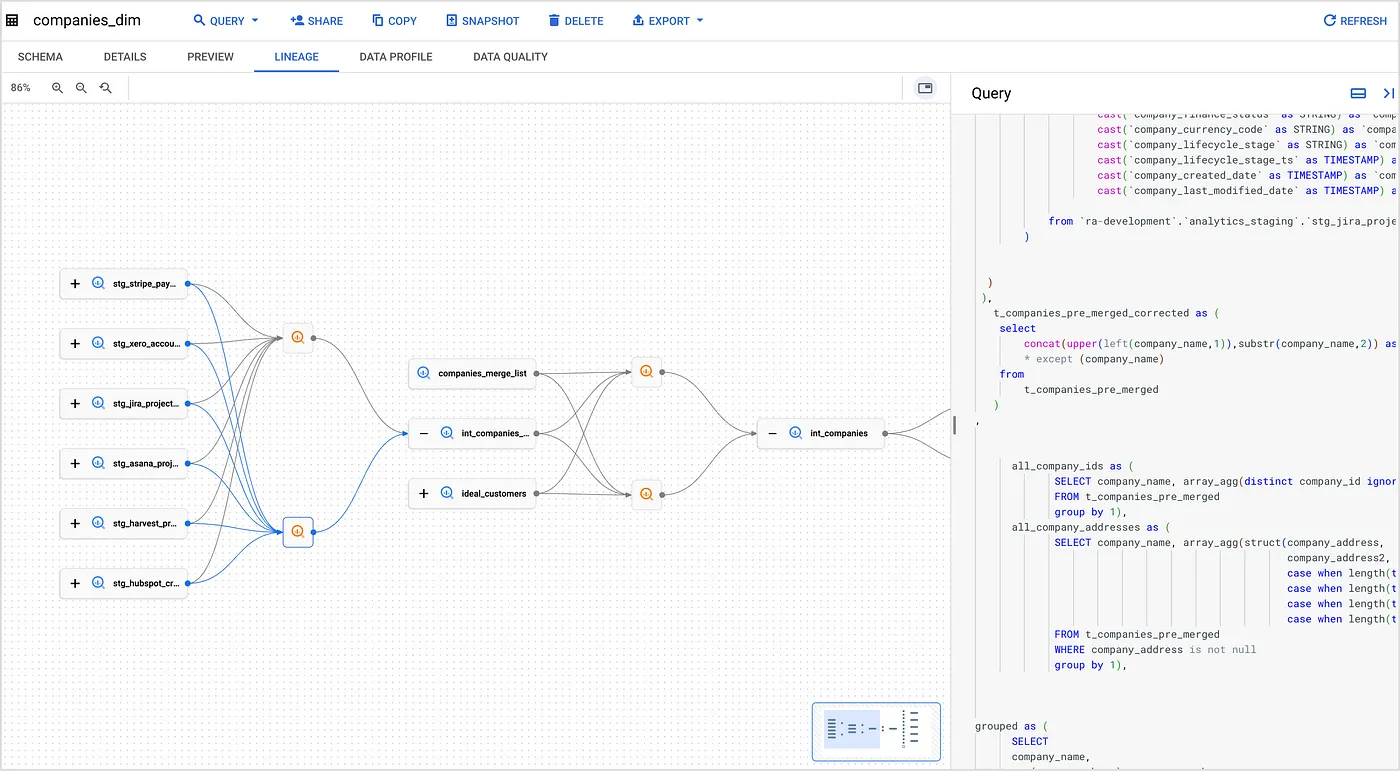
Within this graph, rectangular buttons represent data entities (tables, views, etc.) and square buttons with icons represent processes (BigQuery jobs).
The graph shows how data moves between sources and targets through various processes and you can hover over the process buttons to see details like job ID and attributes, as well as click them on them to view the SQL code (if available), as the screenshot above showed.
If the transformation pipeline for one of your tables included Cloud Composer tasks or Dataproc Spark jobs, you’ll also see these in the Data Lineage tab for that table in the BigQuery web UI or Data Catalog.
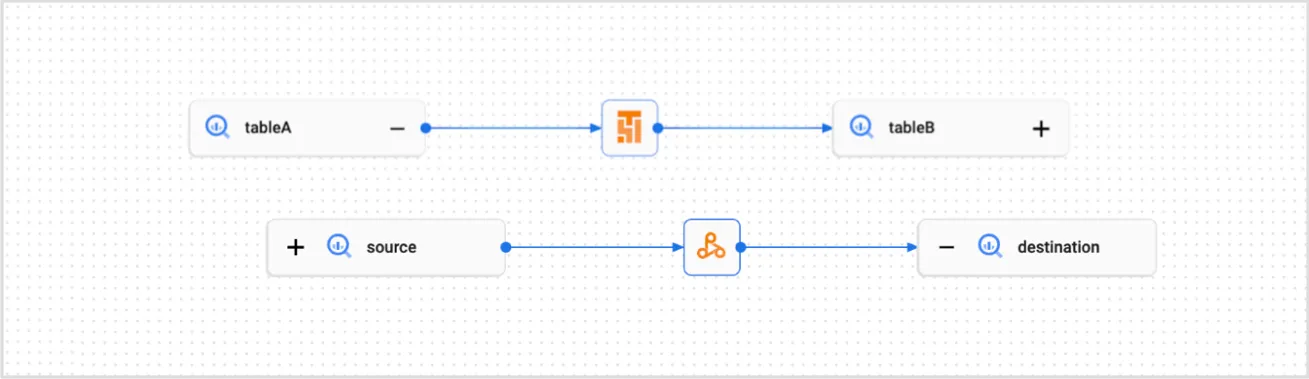
There are however limitation in this first implementation of data lineage within Google Cloud Dataplex that should be noted:
Custom Logic Within dbt Models: Dataplex primarily tracks lineage for data movement between tables but some complex custom logic within dbt models might not be reflected in the lineage visualization or shown in a potentially-confusing way, for example when an incremental refresh is implemented in dbt Core by creating a temporary table to hold the partitions that the incremental refresh will replace. While functional, this process can produce a confusing BigQuery UI lineage graph output, so understanding how the incremental overwrite strategy operates behind the scenes is important for properly interpreting the lineage visualization.
Unsupported Transformations: Transformations not natively supported by BigQuery or the underlying processing engine (e.g., Cloud Dataproc) might not be captured in the lineage. Refer to the documentation for your chosen data processing tool to understand its supported transformations.
Data Catalog Entry Management: While Dataplex automates lineage for supported tools, maintaining Data Catalog entries for custom data sources or complex transformations might be required. This involves manual configuration to ensure accurate lineage representation.
No Support for Looker (yet): Unlike specialist tools such as Select Star that have for some time supported Looker as an input into data lineage graphs, Dataplex data lineage doesn’t yet extend to LookML views or Looker reports or dashboards as part of your lineage graph
Interested? Find out More
Rittman Analytics is a Google Cloud Partner that specialises in data warehousing, data lakehouses and the modern data stack. We can help you you centralise your data sources, scale your data analytics capability and enable your end-users and data team with best practices and a modern analytics workflow.
If you’re looking for some help and assistance building-out your analytics capabilities or data warehouse on a modern, flexible and modular Google Cloud data stack, contact us now to organize a 100%-free, no-obligation call — we’d love to hear from you and see how we can help make your data analytics vision a reality.
Recommended Posts
Data Lineage for your Google BigQuery, dbt and Cloud Composer Data Pipelines using Dataplex and Data Catalog — Rittman Analytics
How Rittman Analytics uses AI-Augmented Project Delivery to Provide Value to Users, Faster
One Person Many Roles: Designing a Unified Person Dimension in Google BigQuery
