Customer Data Warehouses are the New Customer Data Platform — Rittman Analytics
A couple of weeks ago I posted an article on this blog on Customer 360-Degree Analysis using BigQuery, dbt and new “reverse ETL” tools such as Hightouch and Rudderstack, and this article from Tejas Manohar on the Fivetran blog along with the latest episode of the Drill to Detail Podcast are great introductions to the concept of customer data warehouses as the new customer data platform.
In this article I’m going to talk a bit more about we’ve transformed our customer data warehouse into the core of our new customer data platform, adding segmentation, interest scoring and marketing audiences that we then sync to services such as Facebook Custom Audiences and Intercom.
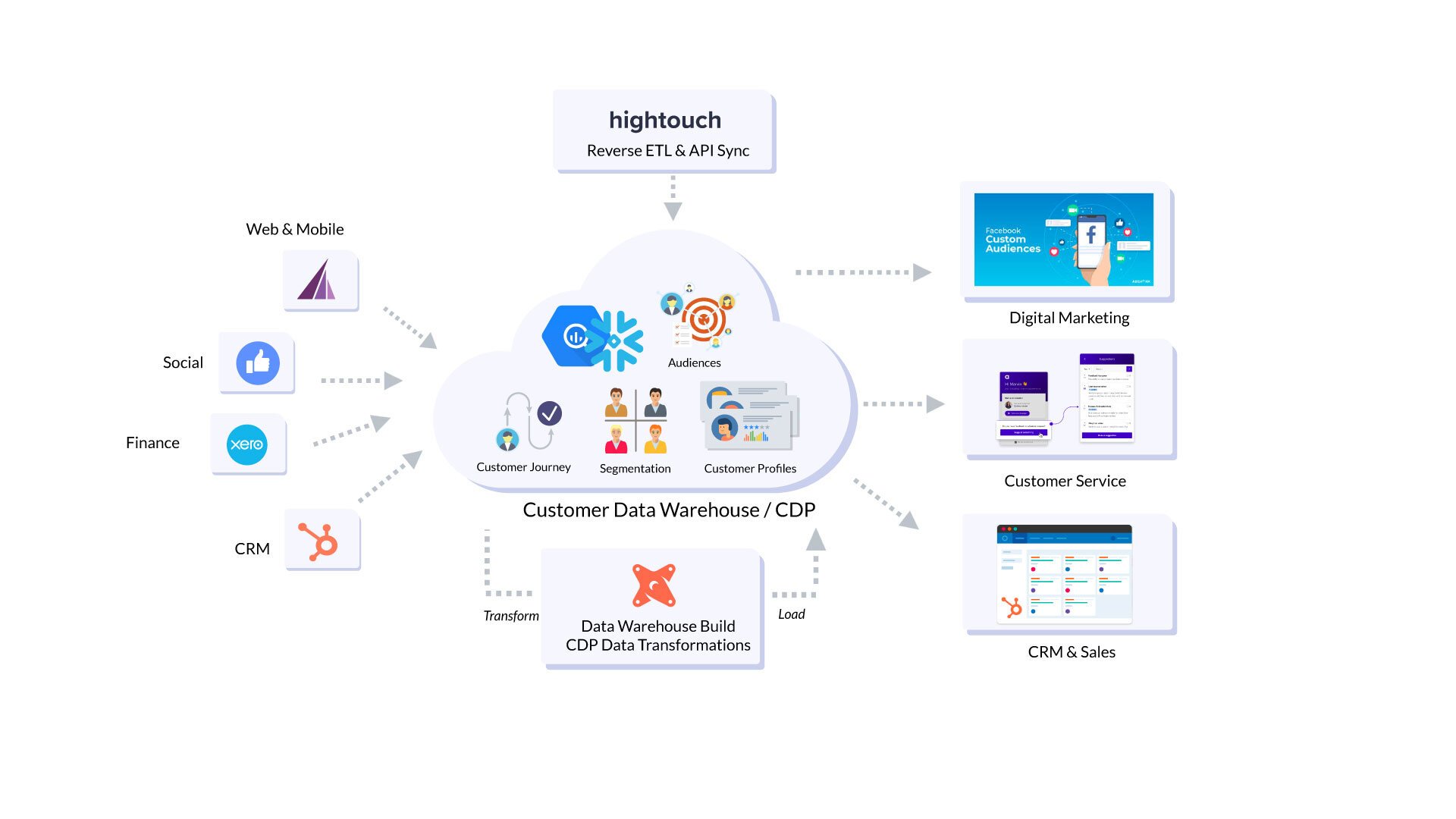
reverse_etl.jpg
reverse_etl.jpg
We do this by creating a set of additional derived customer and contact tables that take data from all parts of our business, both offline and online, and use it to create a set of tables we use to drive our marketing activity.
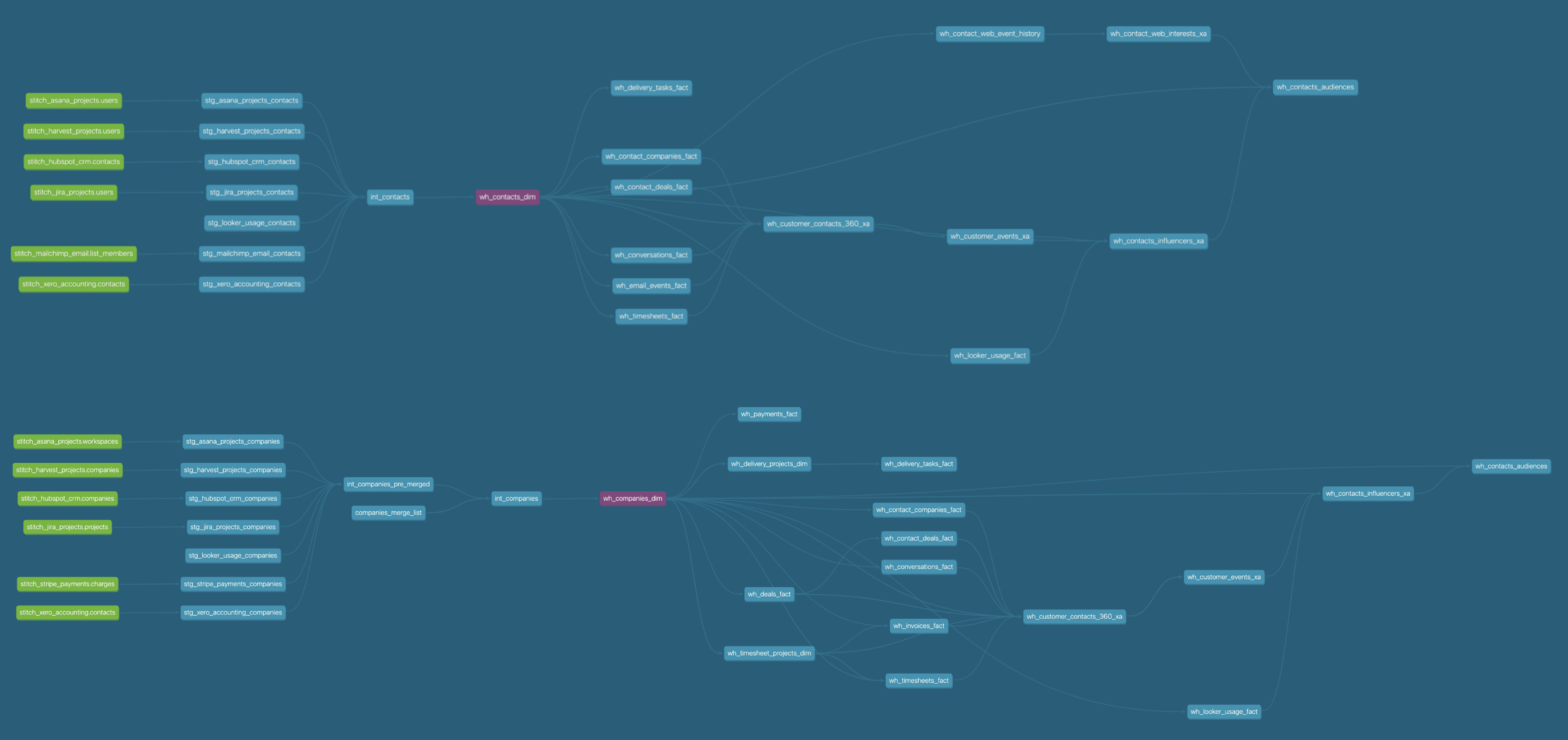
Screenshot 2021-03-12 at 21.01.05.png
Screenshot 2021-03-12 at 21.01.05.png
These additional warehouse tables contain sequenced details of each client’s journey from prospect to opportunity to engaged client, derive sets of behavioral traits we use for marketing personalization and categorise each of the contacts associated with those clients into one of several value segments.
A Data Model for Customer Data Warehouse Data Platforms
The data model diagram below shows these customer data platform tables and how they relate to the customer and contact dimensions in the warehouse:
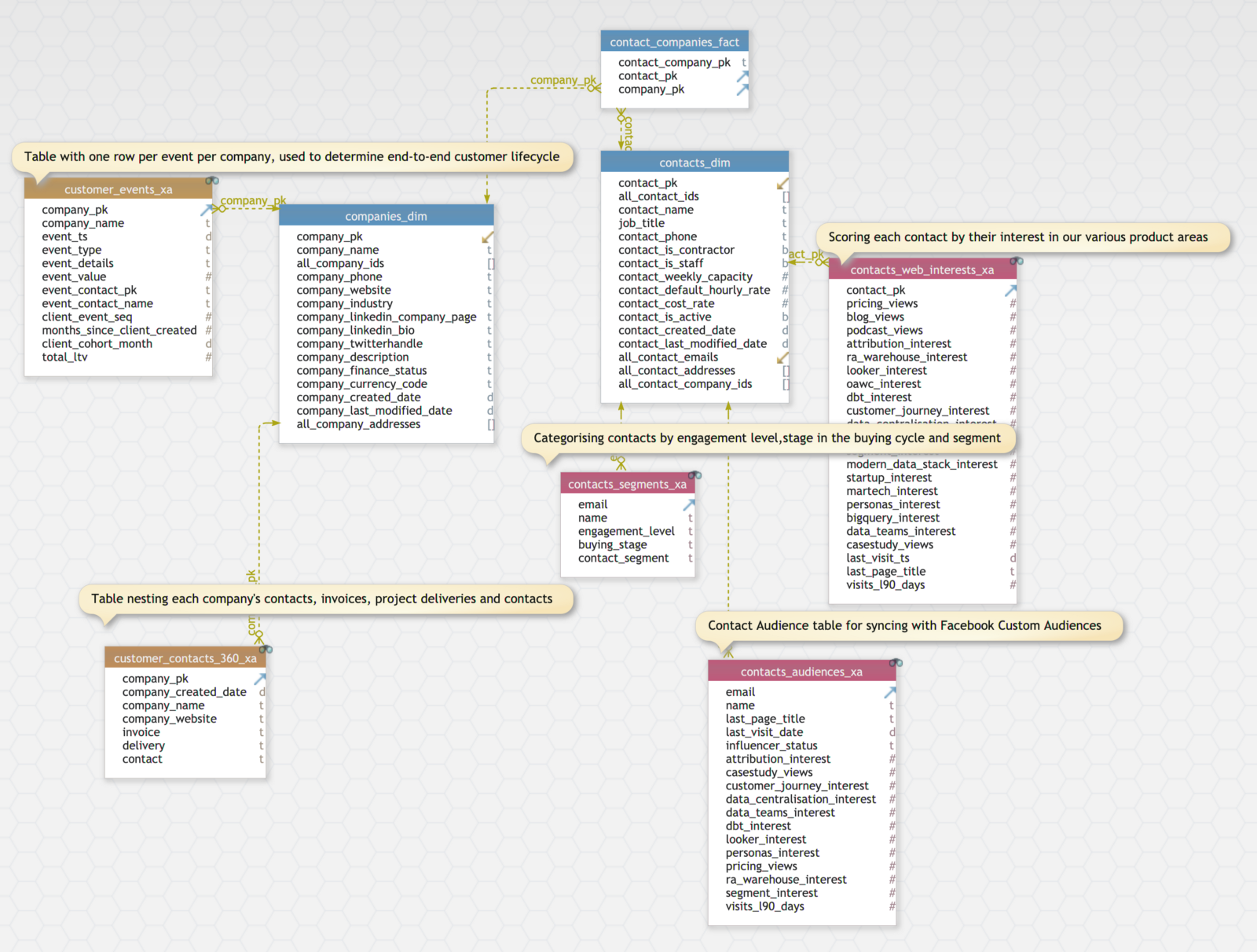
1_zcbekcCWa_-fofr7G0JtaA.png
1_zcbekcCWa_-fofr7G0JtaA.png
These derived tables include (links are to code in our RA Warehouse for dbt Github project, note that the specific examples in that package would need to be adapted for your particular data and requirements)
-
CUSTOMER_EVENTS_XA, a derived table that takes each invoice, timesheet, sales opportunity and contact interaction for a client and turns them into a sequence of events that helps us understand the stage in the customer journey they’re at as well as their profitability at any particular point in time, for example as shown in the Looker visualization below:
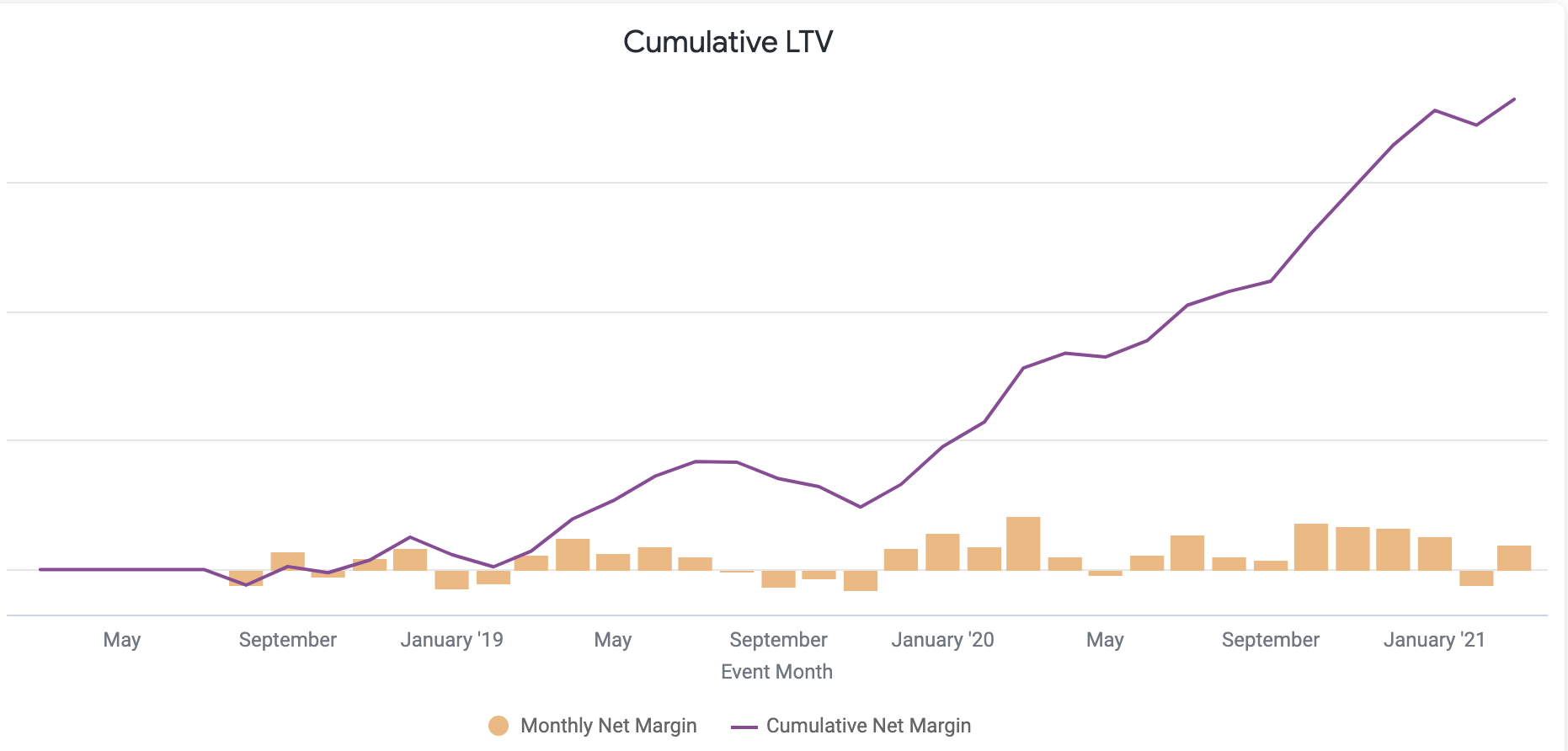
Screenshot 2021-03-12 at 21.43.12.png
Screenshot 2021-03-12 at 21.43.12.png
-
CONTACT_WEB_INTERESTS_XA, where we connect the page view activity recorded for each client contact when they visit our website directly or via links in marketing emails we send, tag those pages with category labels and then use when creating marketing audiences or in summary-level charts such as the one below for all contacts in-aggregate
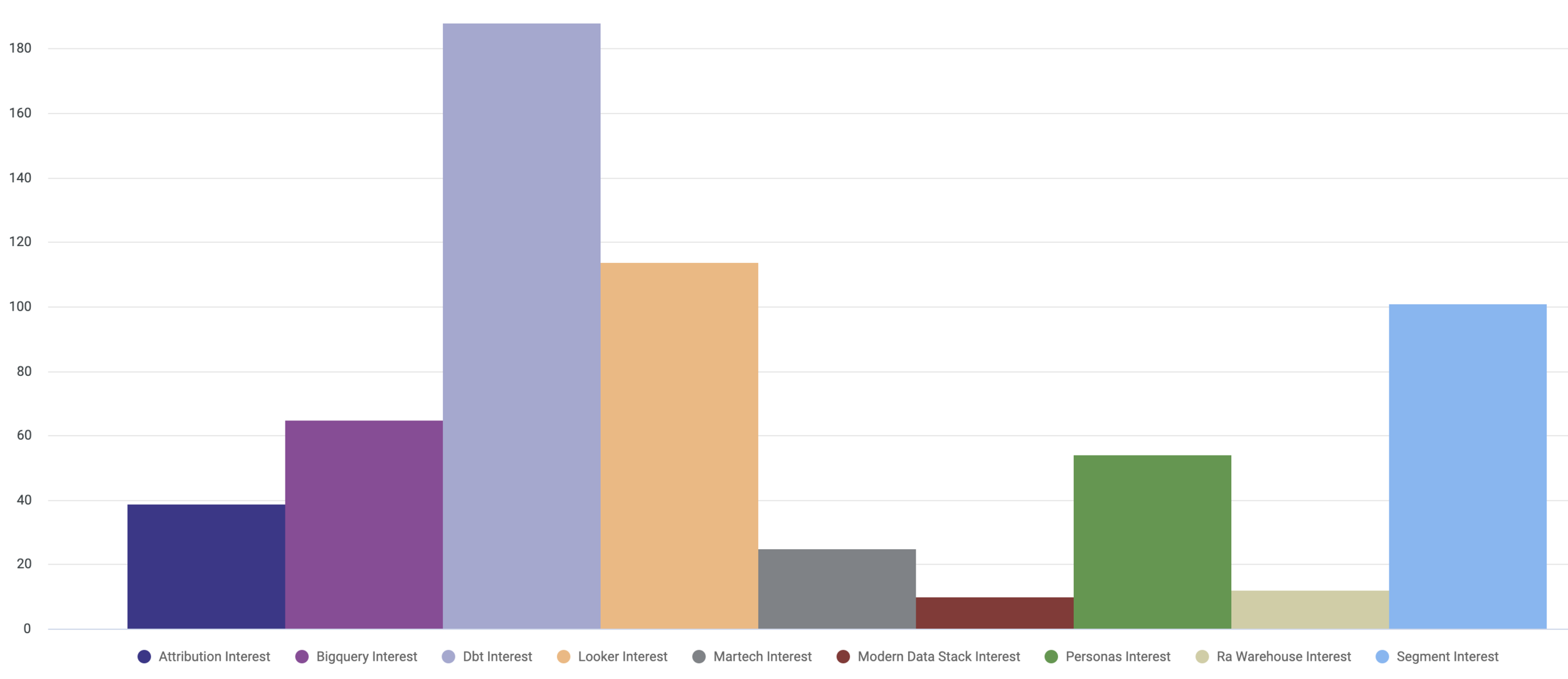
Screenshot 2021-03-12 at 22.08.14.png
Screenshot 2021-03-12 at 22.08.14.png
-
CONTACT_SEGMENTS_XA, where we take the influencer score described in our previous post and use it together with scores for engagement and stage in the buying cycle to place each of our contacts in a value segment as shown in the next Looker visualization and with the aim of our marketing being to move those contacts into segments of higher value over time
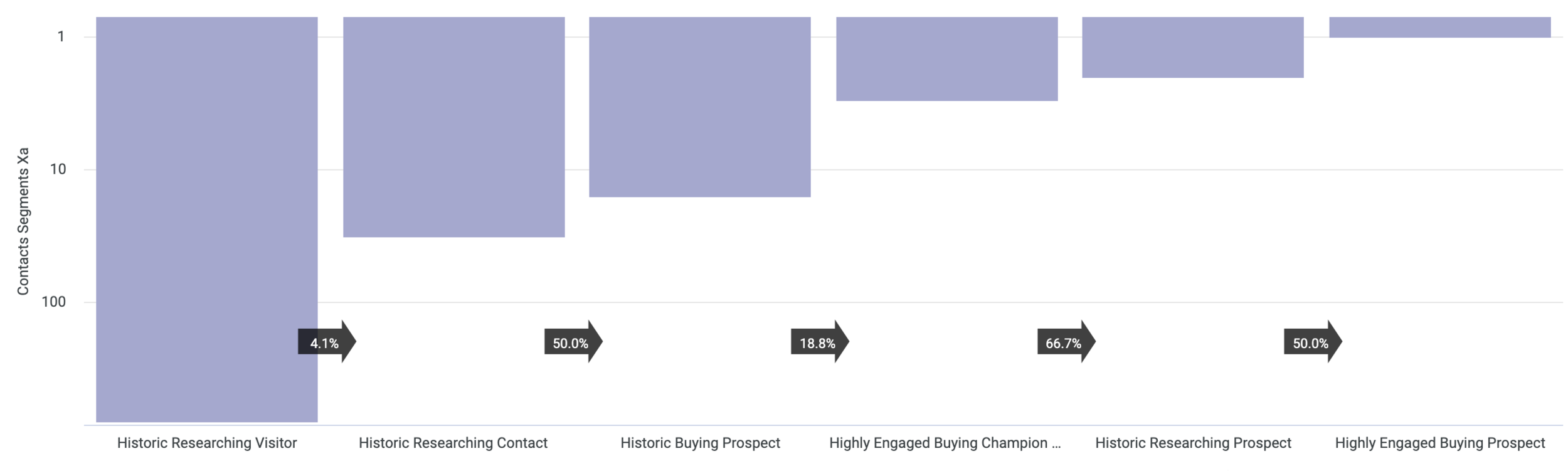
Screenshot 2021-03-12 at 22.26.33.png
Screenshot 2021-03-12 at 22.26.33.png
-
CONTACT_AUDIENCES_XA, the most important table for marketing purposes that takes each of these interest scores, segments and other traits and records them alongside each contact email ready for syncing downstream to our marketing services.
Audience Building and Downstream Syncing of Customer Traits
Now we’ve pulled-together all of this valuable customer and contact marketing data, the next step is to sync it to our various downstream marketing and advertising technology services. For this we’ve been using a new service called Hightouch that I introduced in my previous blog, a tool that allows us to define selections of customer and contact data (or “models”) and then sync those models to various marketing and customer service applications.
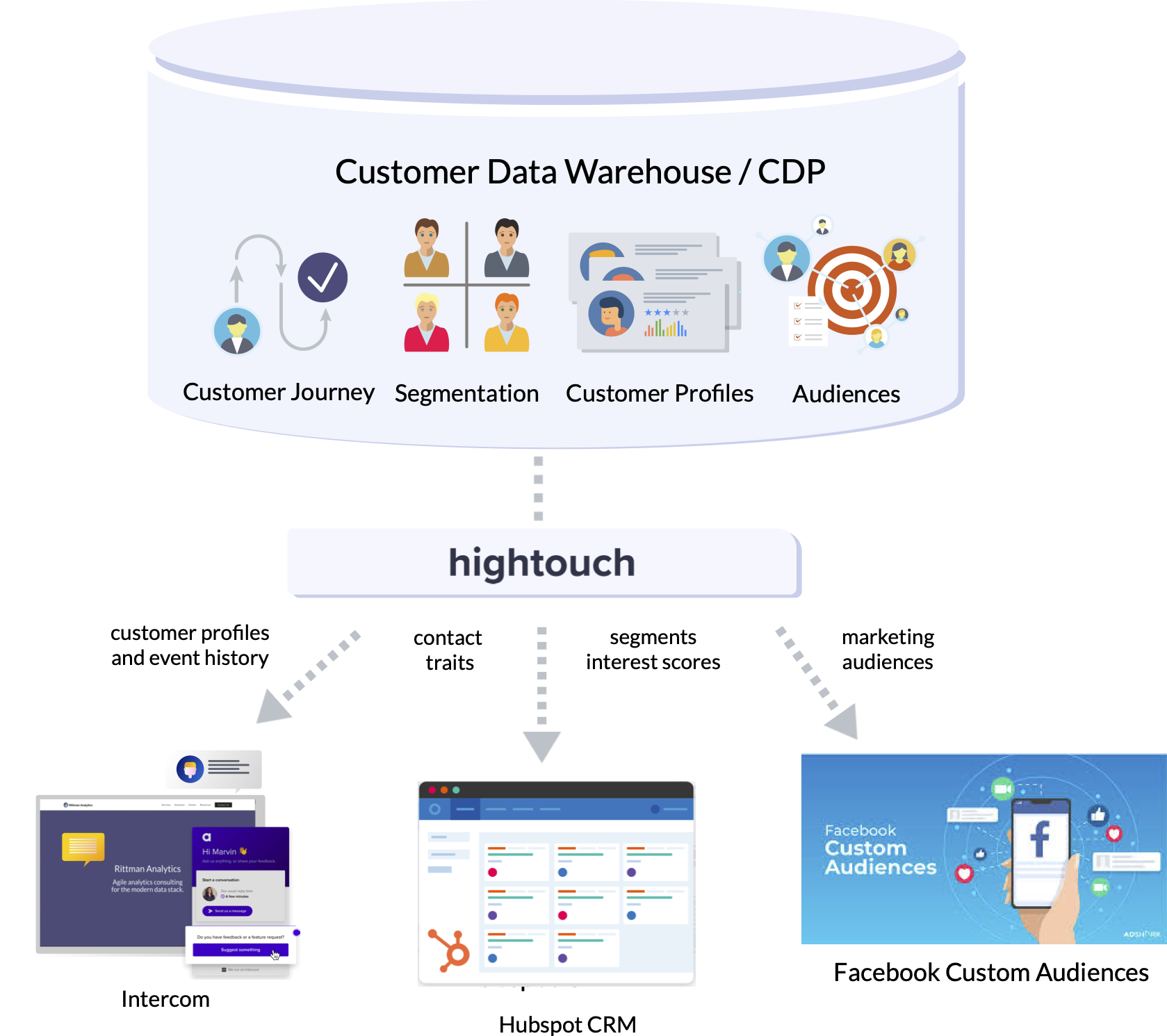
hightouch.png
hightouch.png
Creating a data synchronization job is a three-stage process:
-
Defining a model, a SQL query against the customer data warehouse tables that can either compute traits itself, similar to SQL traits and computed traits in Segment Personas, or can just query a table directly if you’ve already computed those traits as part of your warehouse build.
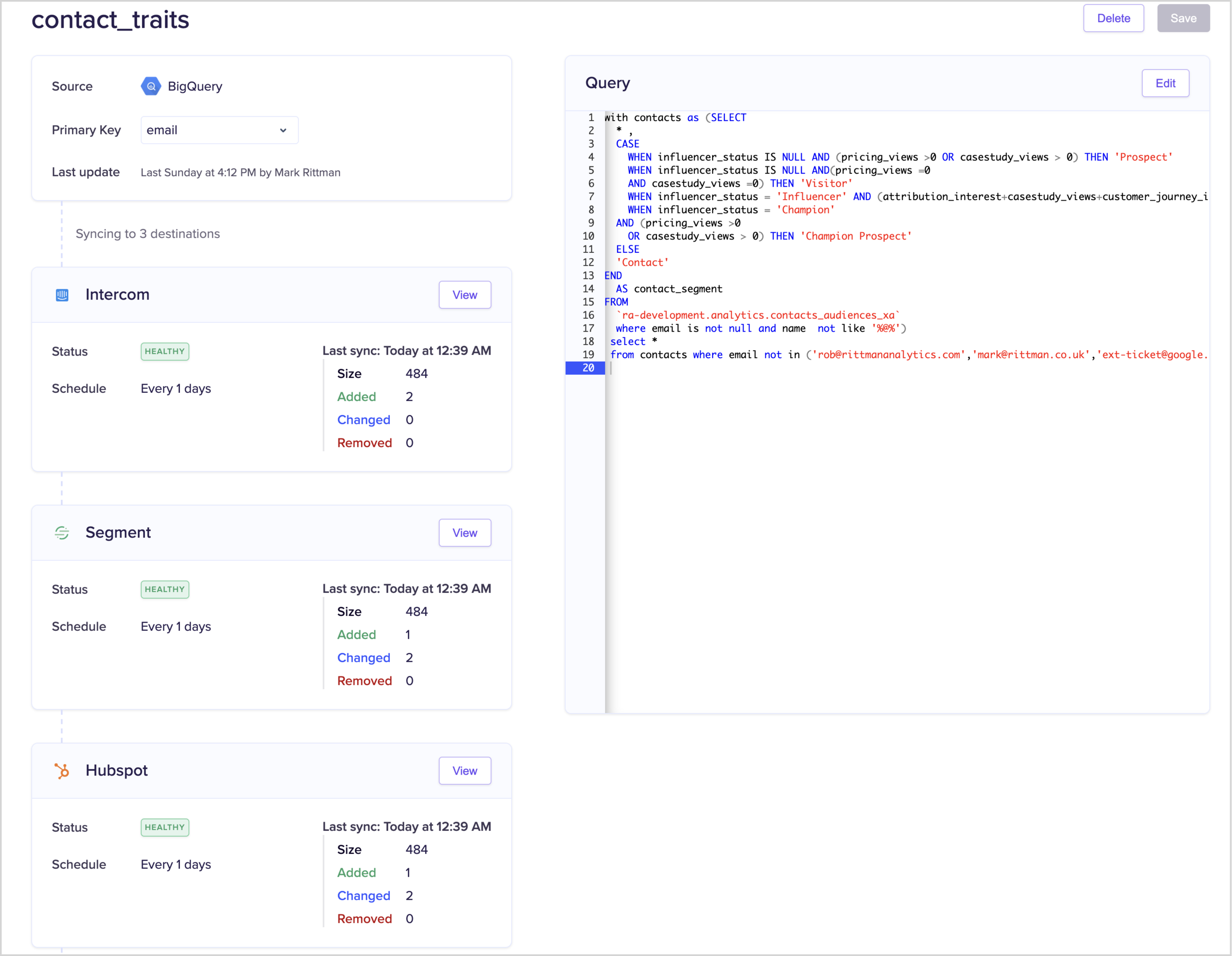
models.png
models.png
2. Connecting to the service you want to sync data to. Hightouch connects via those services APIs and in my case I’ve added Intercom, Facebook Custom Audiences and Hubspot, plus Segment and Rudderstack’s Javascript APIs.
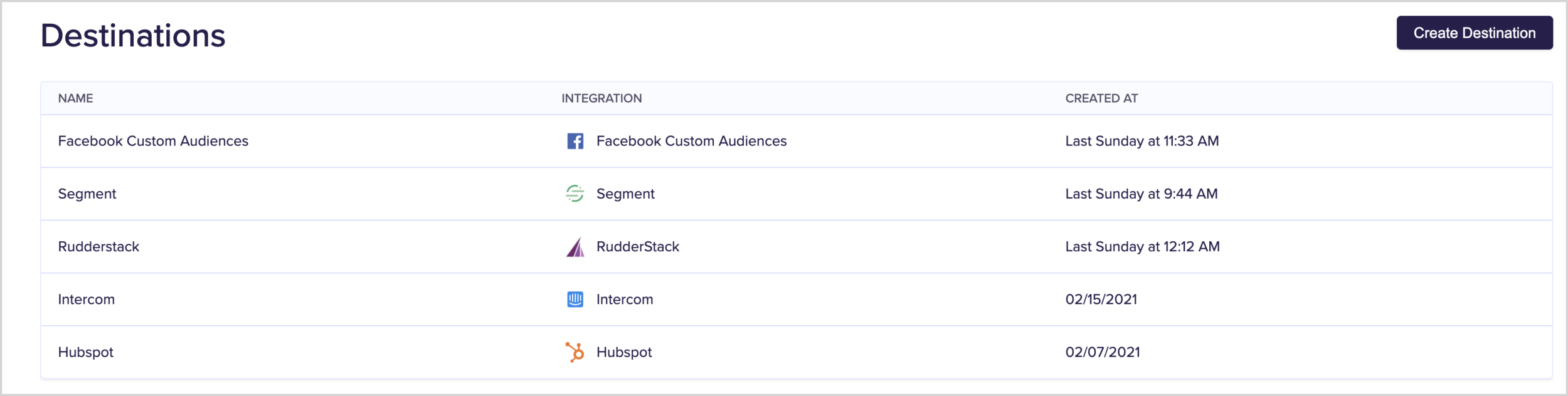
destinations.png
destinations.png
When you sync contact and other data to event collection services such as Segment and Rudderstack they become either user identity events or in the case of Segment, segment entrance and exit track events, or you can send transaction-type data to these services as track events, something we’ve been doing to convert Jira issue data to a series of Segment events in our system.
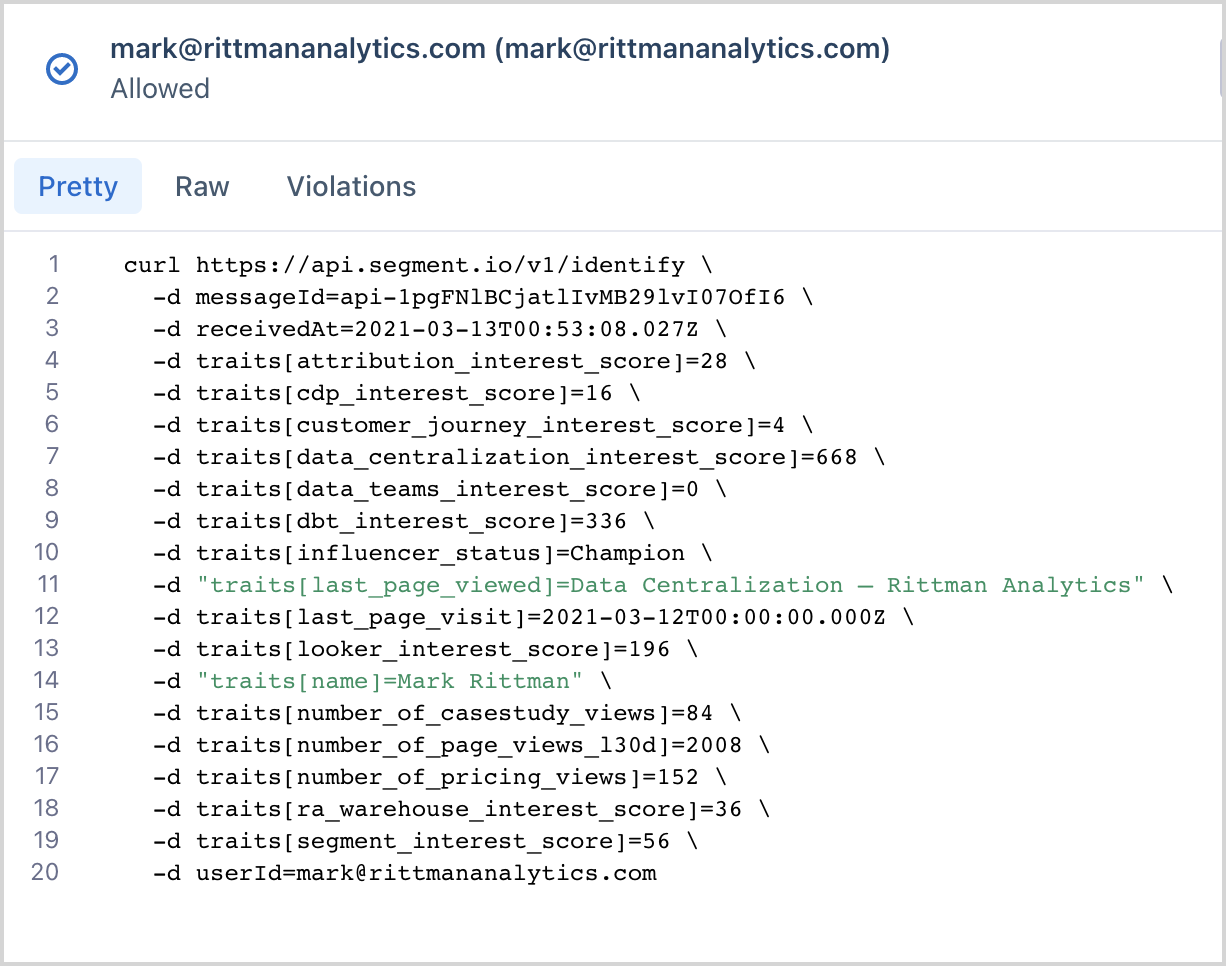
identify.png
identify.png
3. Finally you define the sync itself, which can be triggered either manually, on a schedule or after completion of a dbtCloud job run.
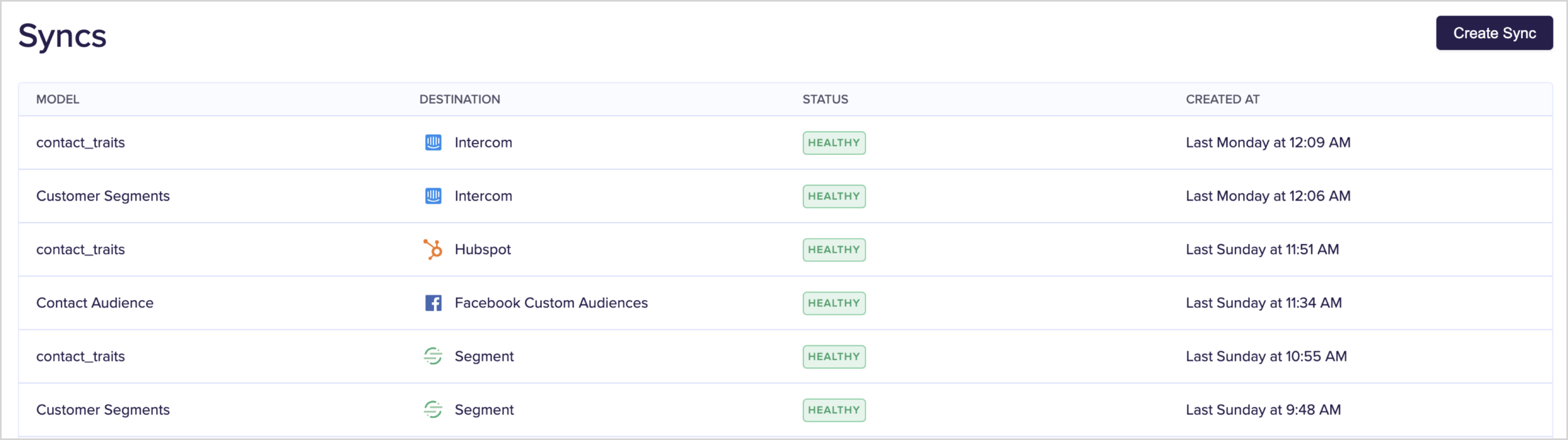
syncs.png
syncs.png
Interested? Find out More
If the idea of creating a customer data platform based around your existing data warehouse and being able to sync that information synced to your downstream marketing and customer applications, contact us now to organise a 100% free, no-obligation 30 minute call to discuss your data needs — we’d love to hear from you.
Recommended Posts
One Person Many Roles: Designing a Unified Person Dimension in Google BigQuery
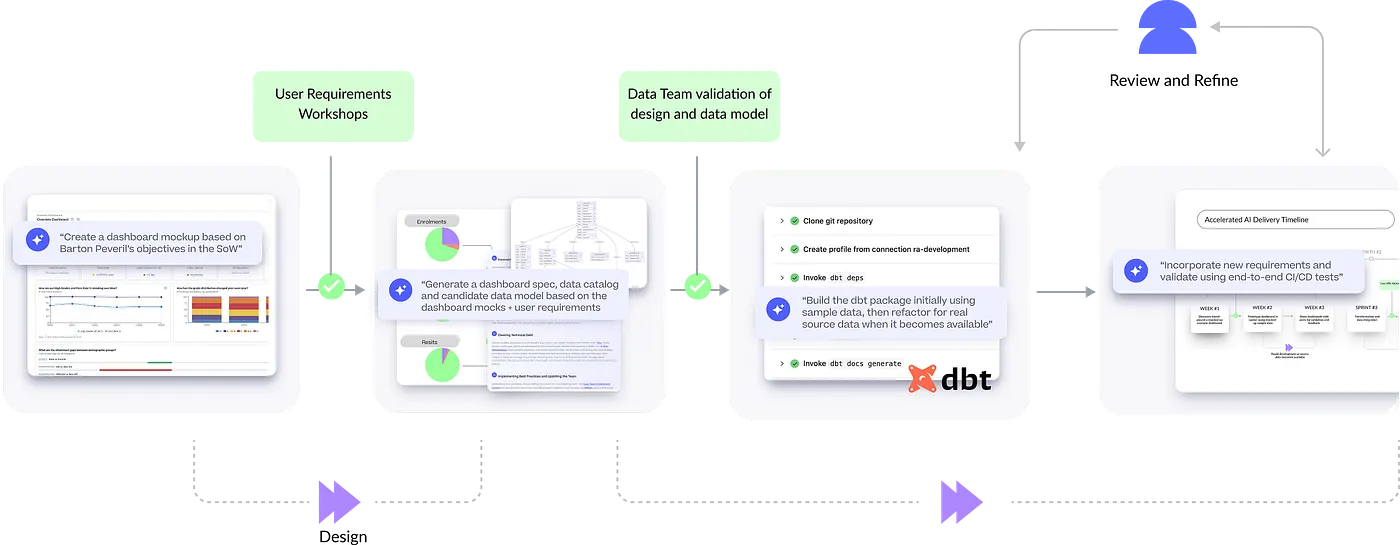
How Rittman Analytics uses AI-Augmented Project Delivery to Provide Value to Users, Faster
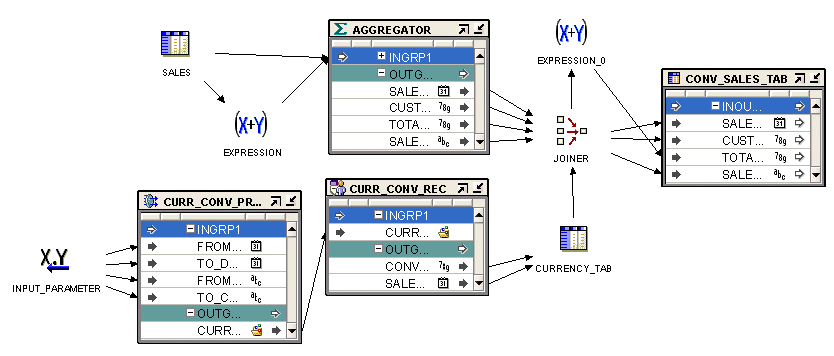
An Homage to Oracle Warehouse Builder, 25 Years Ahead of Its Time
